RDD、DataFrame和DataSet区别
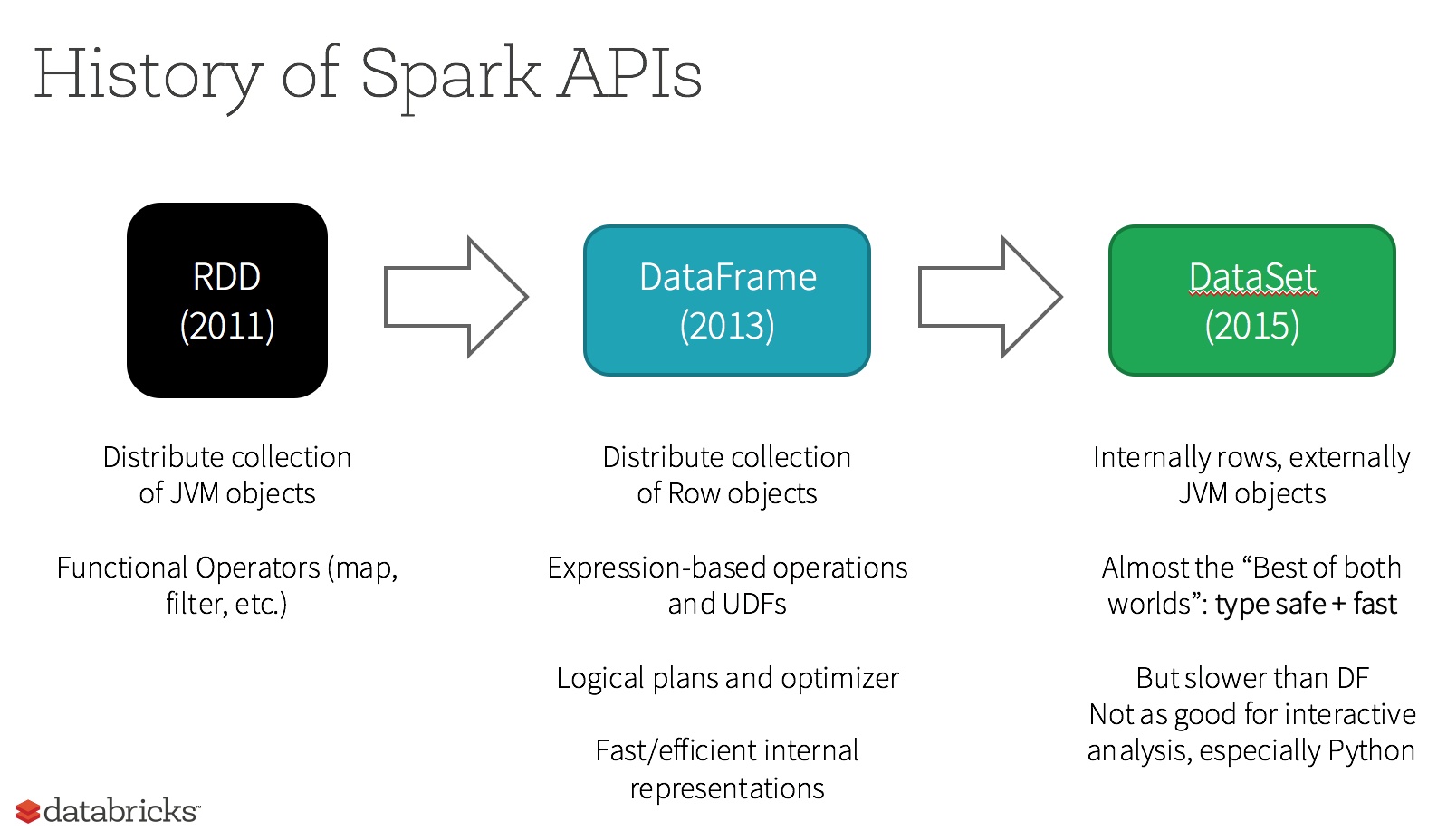
1 RDD
一个RDD就是你的数据的一个不可变的分布式元素集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层API进行并行处理。
使用RDD的场景:
- 你希望可以对你的数据集进行最基本的转换、处理和控制;
- 你的数据是非结构化的,比如流媒体或者字符流;
- 你想通过函数式编程而不是特定领域内的表达来处理你的数据;
- 你不希望像进行列式处理一样定义一个模式,通过名字或字段来处理或访问数据属性;
- 你并不在意通过DataFrame和Dataset进行结构化和半结构化数据处理所能获得的一些优化和性能上的好处;
优点:
- 强大,内置很多函数操作,group,map,filter等,方便处理结构化或非结构化数据
- 面向对象编程,直接存储的java对象,类型转化也安全
缺点:
- 由于它基本和hadoop一样万能的,因此没有针对特殊场景的优化,比如对于结构化数据处理相对于sql来比非常麻烦
- 默认采用的是java序列号方式,序列化结果比较大,而且数据存储在java堆内存中,导致gc比较频繁
2 DataFrame
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame引入了schema。
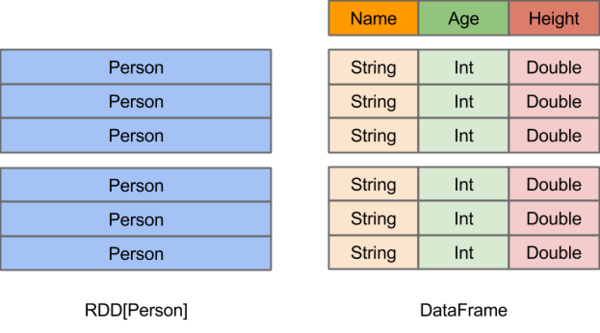
RDD和DataFrame比较:
- 相同之处:都是不可变分布式弹性数据集。
- 不同之处:DataFrame的数据集都是按指定列存储,即结构化数据。类似于传统数据库中的表。
上图直观地体现了DataFrame和RDD的区别。
- 左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。
- RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。
- DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
优点:
- 结构化数据处理非常方便,支持Avro, CSV, elastic search, and Cassandra等kv数据,也支持HIVE tables, MySQL等传统数据表
- 有针对性的优化,由于数据结构元信息spark已经保存,序列化时不需要带上元信息,大大的减少了序列化大小,而且数据保存在堆外内存中,减少了gc次数。
- hive兼容,支持hql,udf等
缺点:
- 编译时不能类型转化安全检查,运行时才能确定是否有问题
- 对于对象支持不友好,rdd内部数据直接以java对象存储,dataframe内存存储的是row对象而不能是自定义对象
3 DataSet
A Dataset is a strongly typed collection of domain-specific objects that can be transformed in parallel using functional or relational operations. Each Dataset also has an untyped view called a DataFrame, which is a Dataset of Row.
Dataset是一个强类型的特定领域的对象,这种对象可以函数式或者关系操作并行地转换。每个Dataset都有一个称为DataFrame的非类型化的视图,这个视图是行的数据集。这种DataFrame是Row类型的Dataset,即Dataset[Row]。
你可以把DataFrame当作一些通用对象Dataset[Row]的集合的一个别名,而一行就是一个通用的无类型的JVM对象。与之形成对比,Dataset就是一些有明确类型定义的JVM对象的集合,通过你在Scala中定义的Case Class或者Java中的Class来指定。
Dataset是“懒惰”的,只在执行行动操作时触发计算。本质上,数据集表示一个逻辑计划,该计划描述了产生数据所需的计算。当执行行动操作时,Spark的查询优化程序优化逻辑计划,并生成一个高效的并行和分布式物理计划。
DataSet和RDD主要的区别是:DataSet是特定域的对象集合;然而RDD是任何对象的集合。DataSet的API总是强类型的;而且可以利用这些模式进行优化,然而RDD却不行。
优点:
- dataset整合了rdd和dataframe的优点,支持结构化和非结构化数据
- 和rdd一样,支持自定义对象存储
- 和dataframe一样,支持结构化数据的sql查询
- 采用堆外内存存储,gc友好
- 类型转化安全,代码友好
- 官方建议使用dataset
参考文献
且谈Apache Spark的API三剑客:RDD、DataFrame和Dataset
如何理解spark中RDD和DataFrame的结构?
平易近人、兼容并蓄——Spark SQL 1.3.0概览
spark core组件:RDD、DataFrame和DataSet介绍、场景与比较
Spark 2.0介绍:从RDD API迁移到DataSet API