HFile结构
HFile是HBase进行数据存储时的实际存储文件。
1 HFile中的Block
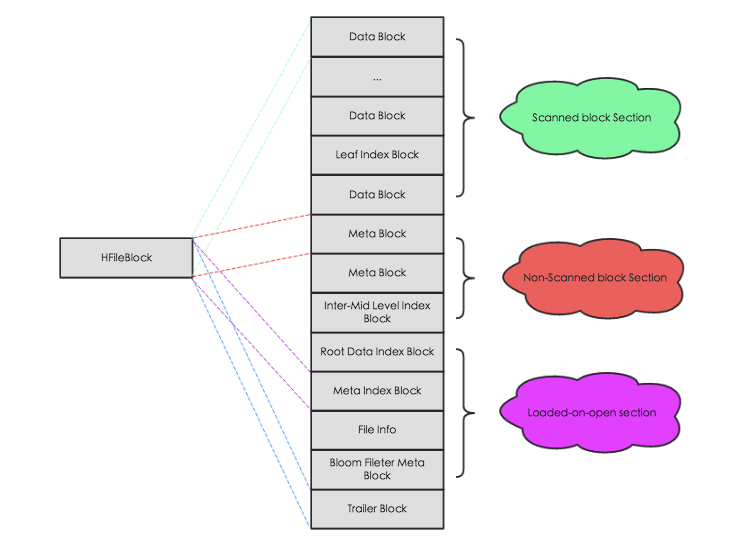
逻辑上包含以下几个部分:
- Scanned block section: 在 HBase 顺序扫描 HFiles 的时候需要被读取的块内容;
- Non-scanned block section: 在 HBase 顺序扫描 HFiles 的时候不会被读取的块内容,主要包括Meta Block和Intermediate Level Data Index Blocks两部分;
- Load-on-open-section: 这部分数据在region server启动时,需要被加载到 BlockCache 中。包括FileInfo、Bloom filter block、data block index和meta block index;
- Trailer: 这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
HFile会被切分为多个大小相等的block块,每个block的大小可以在创建表列簇的时候通过参数blocksize=65535进行指定,默认为64k,大号的Block有利于顺序Scan,小号Block利于随机查询。而且所有block块都拥有相同的数据结构,如图左侧所示,HBase将block块抽象为一个统一的HFileBlock。
HBase中Block分为四种类型:Data Block,Index Block,Bloom Block和Meta Block。
- Data Block用于存储实际数据,通常情况下每个Data Block可以存放多条KeyValue数据对;
- Index Block和Bloom Block都用于优化随机读的查找路径,其中Index Block通过存储索引数据加快数据查找,而Bloom Block通过一定算法可以过滤掉部分一定不存在待查KeyValue的数据文件,减少不必要的IO操作;
- Meta Block主要存储整个HFile的元数据。
2 BloomFilter(布隆过滤器)
2.1 主要功能
提高随机读的性能。
2.2 原理
Bloom Filter使用位数组来实现过滤,初始状态下位数组每一位都为0,如下图所示:

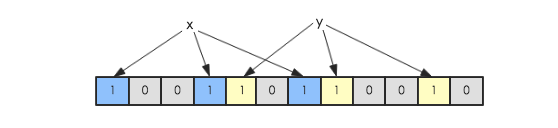
假如此时有一个集合S = {x1, x2, … xn},Bloom Filter使用k个独立的hash函数,分别将集合中的每一个元素映射到{1,…,m}的范围。对于任何一个元素,被映射到的数字作为对应的位数组的索引,该位会被置为1。比如元素x1被hash函数映射到数字8,那么位数组的第8位就会被置为1。下图中集合S只有两个元素x和y,分别被3个hash函数进行映射,映射到的位置分别为(0,3,6)和(4,7,10),对应的位会被置为1:
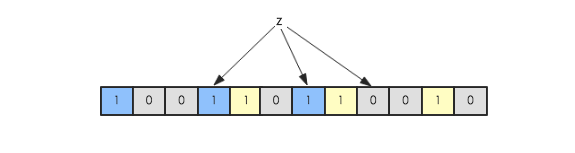
现在假如要判断另一个元素是否是在此集合中,只需要被这3个hash函数进行映射,查看对应的位置是否有0存在,如果有的话,表示此元素肯定不存在于这个集合,否则有可能存在。下图所示就表示z肯定不在集合{x,y}中:
HBase中每个HFile都有对应的位数组,KeyValue在写入HFile时会先经过几个hash函数的映射,映射后将对应的数组位改为1,get请求进来之后再进行hash映射,如果在对应数组位上存在0,说明该get请求查询的数据不在该HFile中。
2.3 存储开销
bloom filter的数据存在StoreFile的meta中,一旦写入无法更新,因为StoreFile是不可变的。Bloomfilter是一个列族(cf)级别的配置属性,如果你在表中设置了Bloomfilter,那么HBase会在生成StoreFile时包含一份bloomfilter结构的数据,称其为MetaBlock;MetaBlock与DataBlock(真实的KeyValue数据)一起由LRUBlockCache维护。所以,开启bloomfilter会有一定的存储及内存cache开销。
2.4 控制粒度
2.4.1 ROW
根据KeyValue中的row来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r3 cf:q1 v)、kv4(r4 cf:q1 v)
如果设置了CF属性中的bloomfilter为ROW,那么get(r1)时就会过滤sf2,get(r3)就会过滤sf1
2.4.2 ROWCOL
根据KeyValue中的row+qualifier来过滤storefile
举例:假设有2个storefile文件sf1和sf2,
sf1包含kv1(r1 cf:q1 v)、kv2(r2 cf:q1 v)
sf2包含kv3(r1 cf:q2 v)、kv4(r2 cf:q2 v)
如果设置了CF属性中的bloomfilter为ROW,无论get(r1,q1)还是get(r1,q2),都会读取sf1+sf2;而如果设置了CF属性中的bloomfilter为ROWCOL,那么get(r1,q1)就会过滤sf2,get(r1,q2)就会过滤sf1
2.5 常用场景
- 根据key随机读时,在StoreFile级别进行过滤
- 读数据时,会查询到大量不存在的key,也可用于高效判断key是否存在
参考文献
HBase – 存储文件HFile结构解析
HBase – 探索HFile索引机制
初涉 HBase
Hbase 布隆过滤器BloomFilter介绍