HBase读写流程
HBase作为一种高可靠、高性能、面向列、可伸缩的分布式存储系统,读操作写操作是该系统中使用最频繁的两种操作,这篇文章我将详细介绍HBase中读操作和写操作的执行流程。
1 WAL机制
WAL(Write-Ahead Logging)是一种高效的日志算法,几乎是所有非内存数据库提升写性能的不二法门,基本原理是在数据写入之前首先顺序写入日志,然后再写入缓存,等到缓存写满之后统一落盘。之所以能够提升写性能,是因为WAL将一次随机写转化为了一次顺序写加一次内存写。提升写性能的同时,WAL可以保证数据的可靠性,即在任何情况下数据不丢失。假如一次写入完成之后发生了宕机,即使所有缓存中的数据丢失,也可以通过恢复日志还原出丢失的数据。
WAL(Write-Ahead-Log)预写日志是HBase的RegionServer在处理数据插入和删除的过程中用来记录操作内容的一种日志。只有当WAL日志写成功以后,客户端才会被告诉提交数据成功,如果写WAL失败会告知客户端提交失败。
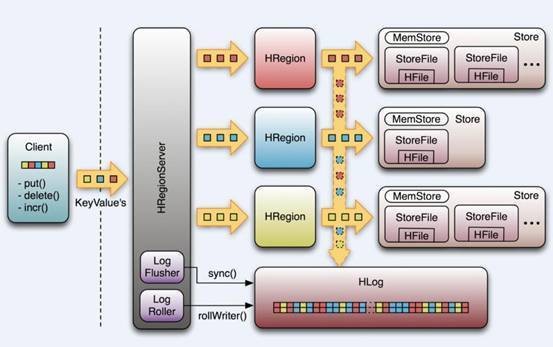
WAL的实现类是HLog,当一个Region被初始化的时候,一个HLog的实例会作为构造函数的参数传进去。
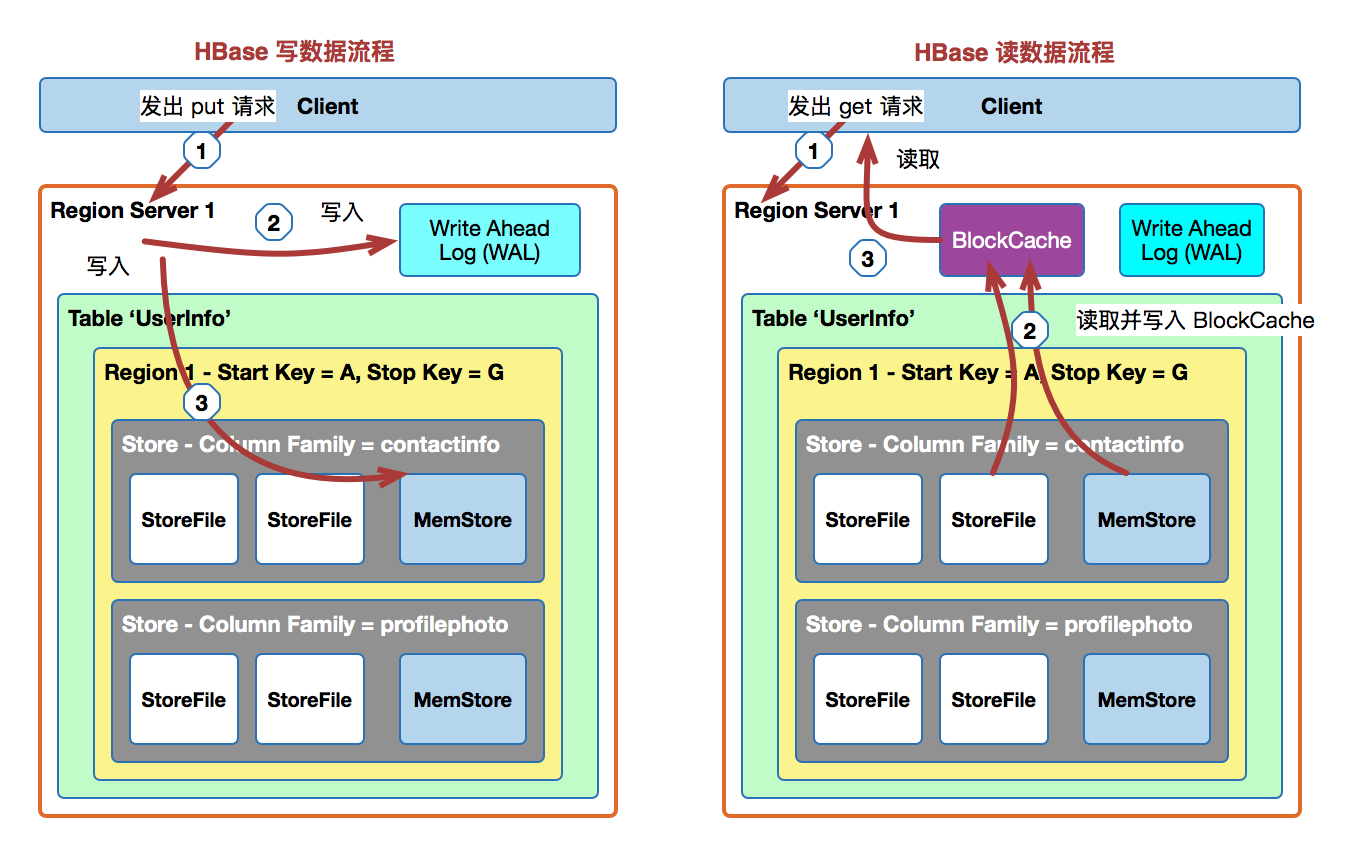
2 写流程
- zookeeper中存储了root表,表中有meta表的region信息,定位到对应的regionserver去读取对应的meta表;
- 根据rowkey、表名在meta表中找到对应的可以存储该条记录的HRegionServer ,访问指定的HRegionServer;
- 先将Put操作写入WAL日志,然后将Put数据保存到MemStore中,同时检查MemStore状态,如果满了(hbase.hregion.memstore.flush.size,默认128MB),则触发Flush to Disk请求;
- 每次flush就会将数据写成HFile文件并存到HDFS上,并且存储最后写入的数据序列号,这样就可以知道哪些数据已经存入了永久存储的HDFS中;
- 当文件达到一定数量(默认3)就会触发Compact操作,将多个HFile合并成一个的HFile文件,同时进行版本合并和数据删除;
- 并保证文件的总数在可控范围之内,major合并最后将文件集中的合并成一个文件,此后刷写又会不断创建小文件。
- 当HFile越来越大,导致单个HFile大小超过一定阈值(默认10G)后,触发Split操作,把当前Region Split成2个Region;
- Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上
- 由此过程可知,HBase只是增加数据,所有的更新和删除操作,都是在Compact阶段做的,所以,用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能。
3 读数据
- Client会通过内部缓存的相关的-ROOT-中的信息和.META.中的信息直接连接与请求数据匹配的HRegionserver(0.98.8版本是在系统表meta中);
- 然后直接定位到该服务器上与客户请求对应的region,客户请求首先会查询该region在内存中的缓存——memstore(memstore是是一个按key排序的树形结构的缓冲区);
- 如果在memstore中查到结果则直接将结果返回给client;
- 在memstore中没有查到匹配的数据,接下来会读已持久化的storefile文件(HFile)中的数据。storefile也是按key排序的树形结构的文件——并且是特别为范围查询或block查询优化过的;另外hbase读取磁盘文件是按其基本I/O单元(即 hbase block)读数据的;
- 如果在BlockCache中能查到要找的数据则直接返回结果,否则就去读相应的storefile文件中读取block的数据,如果还没有读到要查的数据,就将该数据block放到HRegion Server的blockcache中,然后接着读block块儿的数据,一直到这样循环的block数据直到找到要请求的数据并返回结果;如果遍历该region中的数据都没有查到要找的数据,最后直接返回null,表示没有找的匹配的数据。当然blockcache会在其大小大于一定的阀值(heapsize hfile.block.cache.size 0.85)后启动基于LRU算法的淘汰机制,将最老最不常用的block删除。
4 HBase随机读写性能
参见HBase读性能怎么样?
HBase是一个写快读慢的系统(当然,这里的慢是相对于写来说的)。若生产环境是一个read heavy场景,可对HBase做读优化,主要手段是:
- 增强系统IO能力(HDFS层面);
- 增大BlockCache;
- 调整Major Compaction策略。
- 若随机读为主,还可以调小blocksize。
- 写:HBase是基于LSM-Tree模型的,所有的数据更新插入操作都首先写入Memstore中(同时会顺序写到日志HLog中),达到指定大小之后再将这些修改操作批量写入磁盘,生成一个新的HFile文件,这种设计可以极大地提升HBase的写入性能;
- 读:HBase在读取数据的时候首先检查请求的数据是否在Memstore,写缓存未命中的话再到读缓存中查找,读缓存还未命中才会到HFile文件中查找,最终返回merged的一个结果给用户。
参考文献
HBase原理-数据读取流程解析
HBase - 数据写入流程解析
HBase原理-迟到的‘数据读取流程’部分细节
HBase最佳实践-读性能优化策略
HBase最佳实践-写性能优化策略
第五章:大数据 の HBase 进阶
HBase的WAL机制
HBase–读写数据
一条数据的HBase之旅,简明HBase入门教程-Read全流程
一条数据的HBase之旅,简明HBase入门教程-Write全流程