Spark读取数据
2019-02-08
1 Spark加载数据
参见Generic Load/Save Functions (通用 加载/保存 功能)
在最简单的形式中, 默认数据源(parquet, 除非另有配置 spark.sql.sources.default )将用于所有操作.
Carpe diem
参见Generic Load/Save Functions (通用 加载/保存 功能)
在最简单的形式中, 默认数据源(parquet, 除非另有配置 spark.sql.sources.default )将用于所有操作.
数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
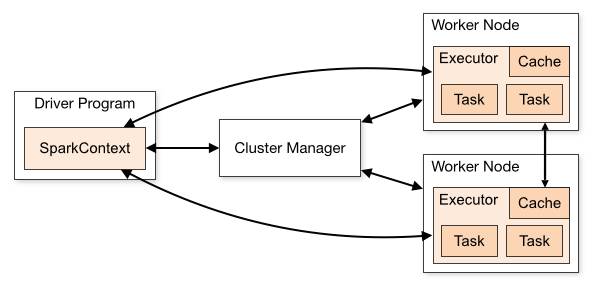
在 Spark 最初采用的静态内存管理机制,存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置,堆内内存的分配如下所示: