Spark Shuffle
Shuffle 过程本质上都是将 Map 端获得的数据使用分区器进行划分,并将数据发送给对应的 Reducer 的过程。
1 MapReduce Shuffle过程
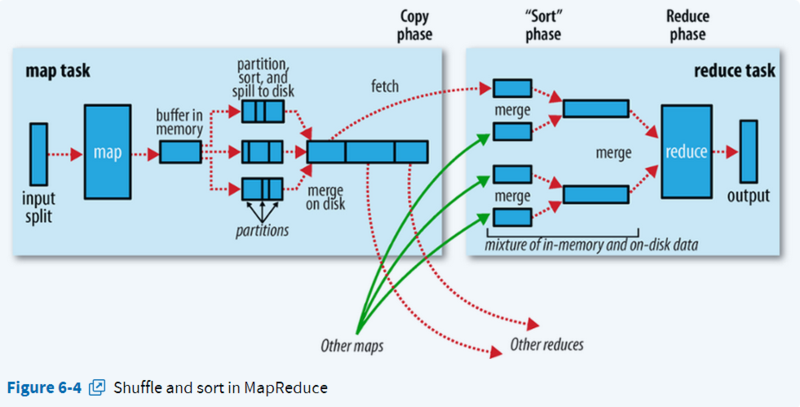
在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据并输出到对应的Reduce;而Reduce阶段负责从Map端拉取数据并进行计算。
- shuffle在map端:partition, sort, spill, merge;
- shuffle在reduce端:copy, merge sort。
2 Spark Shuffle过程
2.1 触发Shuffle的操作
| 操作 | 举例 |
|---|---|
| repartition相关 | repartition、coalesce |
| *ByKey操作 | groupByKey、reduceByKey、combineByKey、aggregateByKey等 |
| join相关 | cogroup、join |
2.2 Spark Shuffle
与MapReduce计算框架一样,Spark的Shuffle实现大致如下图所示,在DAG阶段以shuffle为界,划分stage,上游stage做map task,每个map task将计算结果数据分成多份,每一份对应到下游stage的每个partition中,并将其临时写到磁盘,该过程叫做shuffle write;下游stage做reduce task,每个reduce task通过网络拉取上游stage中所有map task的指定分区结果数据,该过程叫做shuffle read,最后完成reduce的业务逻辑。
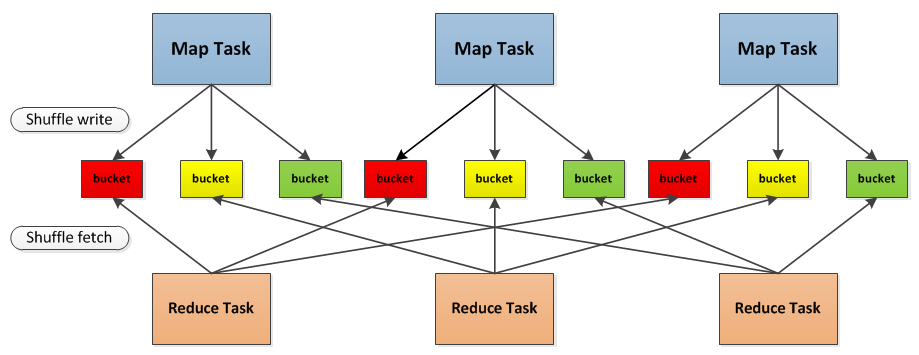
- 首先每一个Mapper会根据Reducer的数量创建出相应的bucket,bucket的数量是
M * R,其中M是Map的个数,R是Reduce的个数。 - 其次Mapper产生的结果会根据设置的partition算法填充到每个bucket中去。这里的partition算法是可以自定义的,当然默认的算法是根据key哈希到不同的bucket中去。
- 当Reducer启动时,它会根据自己task的id和所依赖的Mapper的id从远端或是本地的block manager中取得相应的bucket作为Reducer的输入进行处理。
这里的bucket是一个抽象概念,在实现中每个bucket可以对应一个文件,可以对应文件的一部分或是其他等。
2.3 Shuffle Write
由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内
存存储空间压力,另一方面也是为了容错。 Spark 0.6和0.7的版本中,对于shuffle数据的存储是以文件的方式存储在block manager中,与rdd.persist(StorageLevel.DISk_ONLY)采取相同的策略。
shuffle write 的任务很简单,实现也很简单:将 shuffle write 的处理逻辑加入到 ShuffleMapStage(ShuffleMapTask 所在的 stage) 的最后,该 stage 的 final RDD 每输出一个 record 就将其 partition 并持久化。图示如下:
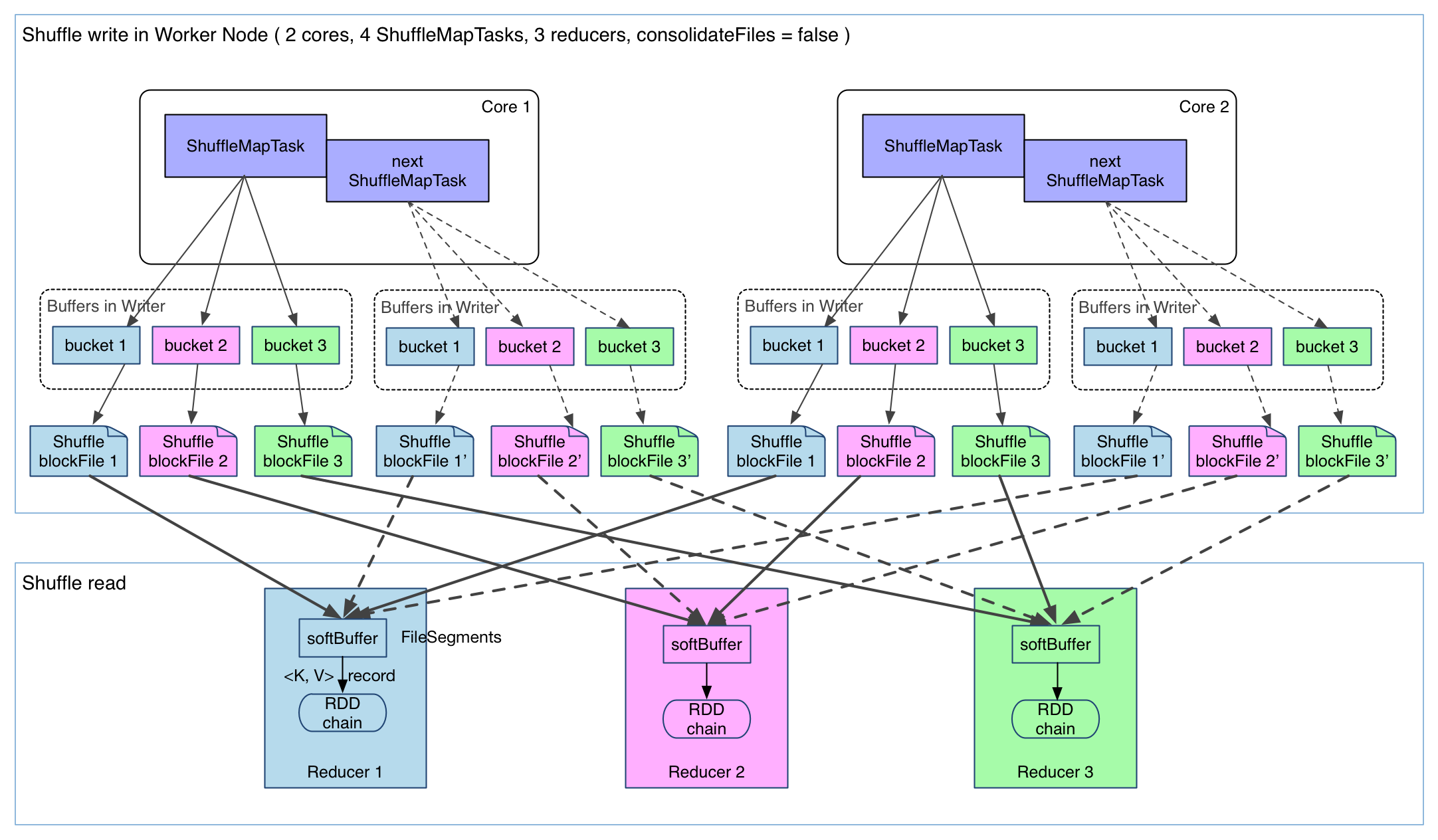
上图有 4 个 ShuffleMapTask 要在同一个 worker node 上运行,CPU core 数为 2,可以同时运行两个 task。每个 task 的
执行结果(该 stage 的 finalRDD 中某个 partition 包含的 records)被逐一写到本地磁盘上。每个 task 包含 R 个缓冲区,R=reducer 个数(也就是下一个 stage 中 task 的个数),缓冲区被称为 bucket,其大小
为 spark.shuffle.file.buffer.kb ,默认是 100KB。
ShuffleMapTask 的执行过程很简单:
- 先利用 pipeline 计算得到 finalRDD 中对应 partition 的 records。
- 每得到一个record就将其送到对应的 bucket 里,具体是哪个 bucket 由
partitioner.partition(record.getKey()))决定。 - 每个bucket里面的数据会不断被写到本地磁盘上,形成一个ShuffleBlockFile,或者简称FileSegment。之后的 reducer 会去 fetch 属于自己的 FileSegment,进入shuffle read阶段。
缺陷:
- 缓冲区占用内存空间大。Map的输出必须先全部存储到内存中,然后写入磁盘。这对内存是一个非常大的开销,当内存不足以存储所有的Map output时就会出现OOM。
- 产生的 FileSegment 过多。每一个Mapper都会产生Reducer number个shuffle文件,如果Mapper个数是1k,Reducer个数也是1k,那么就会产生1M个shuffle文件,这对于文件系统是一个非常大的负担。同时在shuffle数据量不大而shuffle文件又非常多的情况下,随机写也会严重降低I/O的性能。
2.3.1 解决缺陷一
针对第一个问题,在Spark 0.8版本中,shuffle write采用了与RDD block write不同的方式,同时也为shuffle write单独创建了ShuffleBlockManager。由ShuffleBlockManager来分配和管理bucket。同时ShuffleBlockManager为每一个bucket分配一个DiskObjectWriter,每个write handler拥有默认100KB的缓存,使用这个write handler将Map output写入文件中。可以看到现在的写入方式变为buckets.writers(bucketId).write(pair),也就是说Map output的key-value pair是逐个写入到磁盘而不是预先把所有数据存储在内存中在整体flush到磁盘中去。
2.3.2 解决缺陷二
为了解决shuffle文件过多的情况,Spark 0.8.1引入了新的shuffle consolidation,以期显著减少shuffle文件的数量。
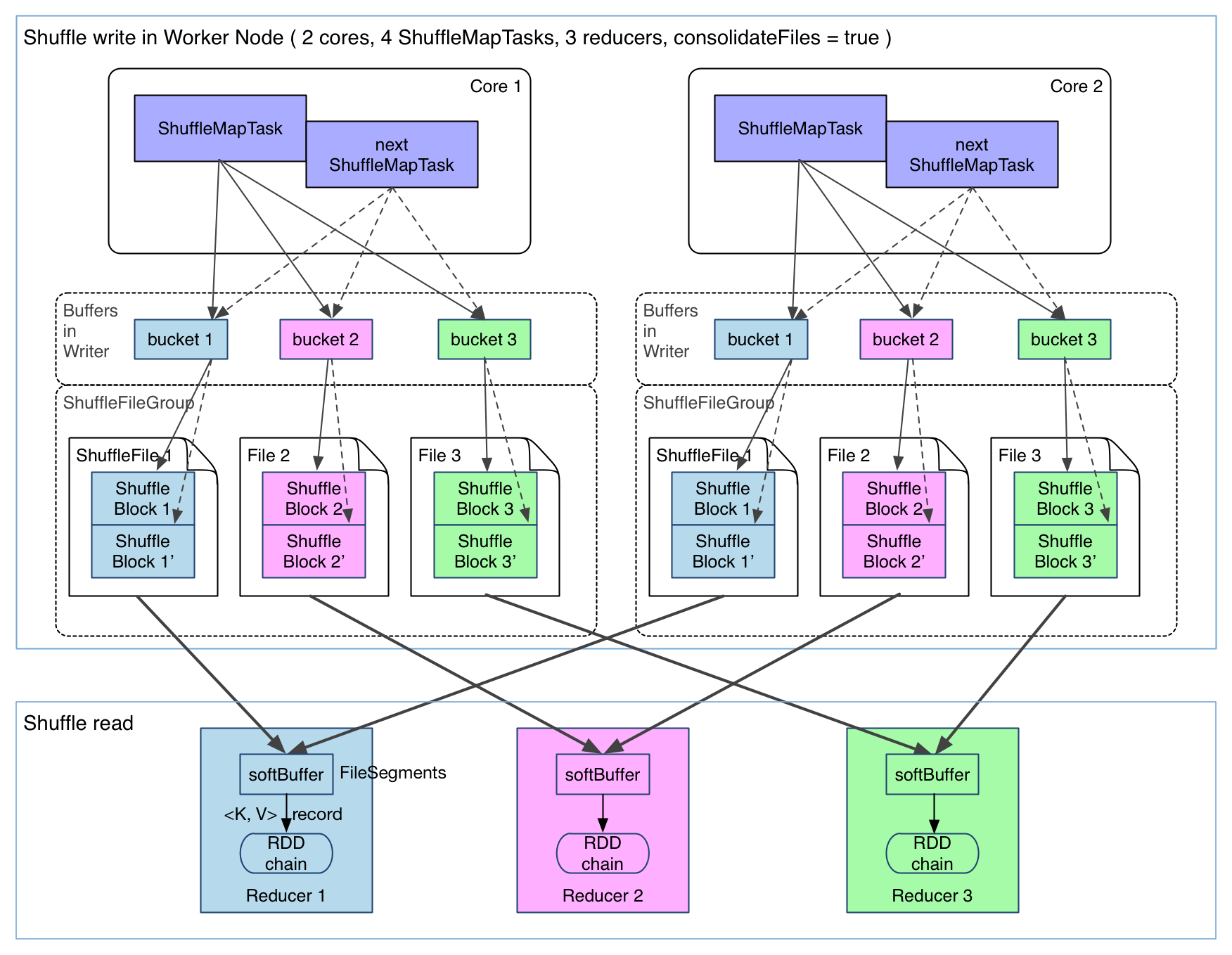
在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的
ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成
ShuffleBlock i',每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行
了。这样,每个 worker 持有的文件数降为 cores * R。FileConsolidation 功能可以通
过 spark.shuffle.consolidateFiles=true来开启。
2.4 Shuffle Fetch and Aggregator
Shuffle write写出去的数据要被Reducer使用,就需要shuffle fetcher将所需的数据fetch过来,这里的fetch包括本地和远端,因为shuffle数据有可能一部分是存储在本地的。
- 在什么时候 fetch?
当 parent stage 的所有 ShuffleMapTasks 结束后再 fetch。 - 边 fetch 边处理还是一次性 fetch 完再处理?
边 fetch 边处理。 - fetch 来的数据存放到哪里?
刚 fetch 来的 FileSegment 存放在 softBuffer 缓冲区,经过处理后的数据放在内存 + 磁盘上。 - 怎么获得要 fetch 的数据的存放位置?
因为 shuffle 过程需要 MapOutputTrackerMaster 来指示 ShuffleMapTask 输出数据的位置。因此,reducer 在 shuffle 的时候是要去driver 里面的 MapOutputTrackerMaster 询问 ShuffleMapTask 输出的数据位置的。每个 ShuffleMapTask 完成时会将FileSegment 的存储位置信息汇报给 MapOutputTrackerMaster。
2.4.1 aggregator
我们都知道在Hadoop MapReduce的shuffle过程中,shuffle fetch过来的数据会进行merge sort,使得相同key下的不同value按序归并到一起供Reducer使用。所有的merge sort都是在磁盘上进行的,有效地控制了内存的使用,但是代价是更多的磁盘IO。
aggregator本质上是一个hashmap,它是以map output的key为key,以任意所要combine的类型为value的hashmap。当我们在做word count reduce计算count值的时候,它会将shuffle fetch到的每一个key-value pair更新或是插入到hashmap中(若在hashmap中没有查找到,则插入其中;若查找到则更新value值)。这样就不需要预先把所有的key-value进行merge sort,而是来一个处理一个,省下了外部排序这一步骤。
3 Spark shuffle和Hadoop shuffle的区别
- 是否需要对key提前进行排序。Hadoop在进行shuffle操作时,提前会对key进行排序。而Spark认为许多应用不需要对key排序,所以默认没有对key进行排序。
- DAG数据流的优势。Hadoop shuffle只能从一个map stage中shuffle数据,而Spark shuffle可以从多个map stage中shuffle数据。
参考文献
详细探究Spark的shuffle实现
通过腾讯shuffle部署对shuffle过程进行详解
Spark Shuffle原理及相关调优
Spark Shuffle概述