Spark基本概念解析
1 Spark基本架构
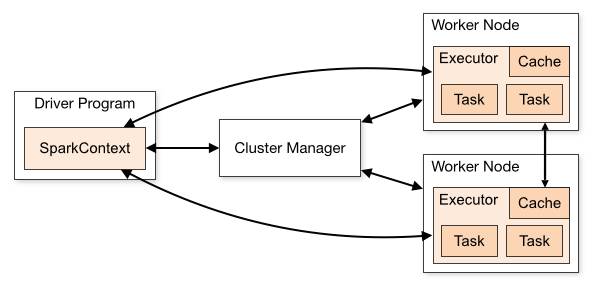
从集群部署的角度来看,Spark集群由以下部分组成:
- Cluster Manager:Spark的集群管理器,主要负责资源的分配与管理。集群管理器分配的资源属于一级分配,它将各个Worker上的内存、CPU等资源分配给应用程序,但是并不负责对Executor的资源分配。目前,Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
- Worker:Spark的工作节点。对Spark应用程序来说,由集群管理器分配得到资源的Worker节点主要负责以下工作:创建Executor,将资源和任务进一步分配给Executor,同步资源信息给Cluster Manager。
- Executor:执行计算任务的一个进程。主要负责任务的执行以及与Worker、Driver Program的信息同步。
- Driver Program:客户端驱动程序,也可以理解为客户端应用程序,运行main函数并创建SparkContext的进程。用于将任务程序转换为RDD和DAG,并与Cluster Manager进行通信与调度。
Spark应用在集群上运行时,包括了多个独立的进程,这些进程之间通过你的主程序(也叫作驱动器,即:driver)中的SparkContext对象来进行协调。
SparkContext能与多种集群管理器通信(包括:Spark独立部署时自带的集群管理器,Mesos或者YARN)。
- 一旦连接上集群管理器,Spark会为该应用在各个集群节点上申请执行器(executor),用于执行计算任务和存储数据。
- 接下来,Spark将应用程序代码(JAR包或者Python文件)发送给所申请到的执行器。
- 最后SparkContext将分割出的任务(task)发送给各个执行器去运行。
注意:
- 每个Spark应用程序对应多个执行器进程,执行器进程在整个应用程序生命周期内,都保持运行状态,并以多线程方式运行所收到的任务。这样的好处是,可以隔离Spark应用。
- 从调度角度来看,每个驱动器可以独立调度本应用程序内部的任务;
- 从执行器角度来看,不同的Spark应用对应的任务将会在不同的JVM中运行。
然而这种架构同样也有其劣势,多个Spark应用程序之间无法共享数据,除非把数据写到外部存储中。
- Spark对底层的集群管理器一无所知。只要Spark能申请到执行器进程,并且能与之通信即可。这种实现方式可以使Spark相对比较容易在一个支持多种应用的集群管理器上运行(如:Mesos或YARN)
- 驱动器(driver)程序在整个生命周期内必须监听并接受其对应的各个执行器的连接请求。因此,驱动器程序必须能够被所有worker节点访问到。
- 因为集群上的任务是由驱动器来调度的,所以驱动器应该和worker节点距离近一些,最好在同一个本地局域网中。如果你需要远程对集群发起请求,最好还是在驱动器节点上启动RPC服务,来响应这些远程请求,同时把驱动器本身放在集群worker节点比较近的机器上。
2 Spark编程模型
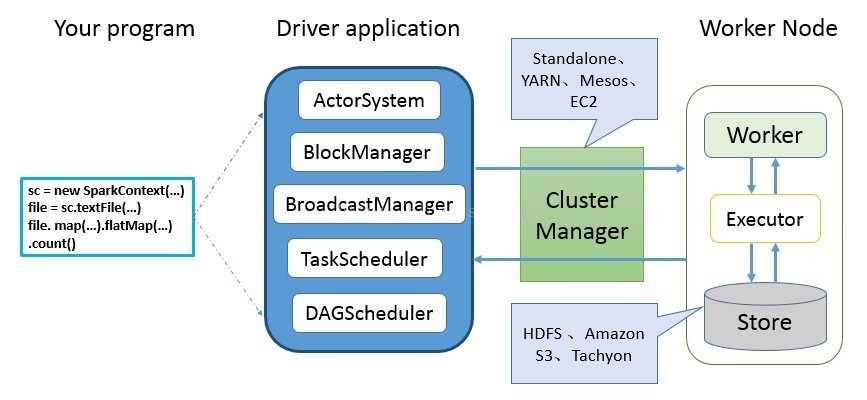
Spark 应用程序从编写到提交、执行、输出的整个过程如上图所示,图中描述的步骤如下:
- 用户使用SparkContext提供的API(常用的有textFile、sequenceFile、runJob、stop等)编写Driver Program程序。此外SQLContext、HiveContext及StreamingContext对SparkContext进行封装,并提供了SQL、Hive及流式计算相关的API。
- 使用SparkContext提交的用户应用程序,首先会使用BlockManager和BroadcastManager将任务的Hadoop配置进行广播。然后由DAGScheduler将任务转换为RDD并组织成DAG,DAG还将被划分为不同的Stage。最后由TaskScheduler借助ActorSystem(类似于RpcEnv,spark 2.x使用Netty代替了Akka)将任务提交给集群管理器(Cluster Manager)。
- 集群管理器(ClusterManager)给任务分配资源,即将具体任务分配到Worker上,Worker创建Executor来处理任务的运行。Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
3 Spark中的概念
3.1 Application
Spark上运行的程序,包含了驱动器(driver)进程(一个)和集群上的执行器(executor)进程(多个)。
3.2 Driver Program
运行main函数并创建SparkContext的进程。定义一个spark应用程序所需要的三大步骤的逻辑:加载数据集,处理数据,结果展示。
3.3 Cluster Manager
集群的资源管理器,用于在集群上申请资源的外部服务(如:独立部署的集群管理器、Mesos或者YARN)。集群管理器分配的资源属于一级分配,它将各个Worker上的内存、CPU等资源分配给应用程序,但是并不负责对Executor的资源分配。
在Standalone模式中即为Master(主节点),控制整个集群,监控Worker。
3.4 Deploy mode(部署模式)
用于区分驱动器进程在哪里运行。在”cluster”模式下,驱动器将运行在集群上某个节点;在”client“模式下,驱动器在集群之外的客户端运行。
3.5 Worker Node
从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager。
3.6 RDD(弹性分布式数据集)
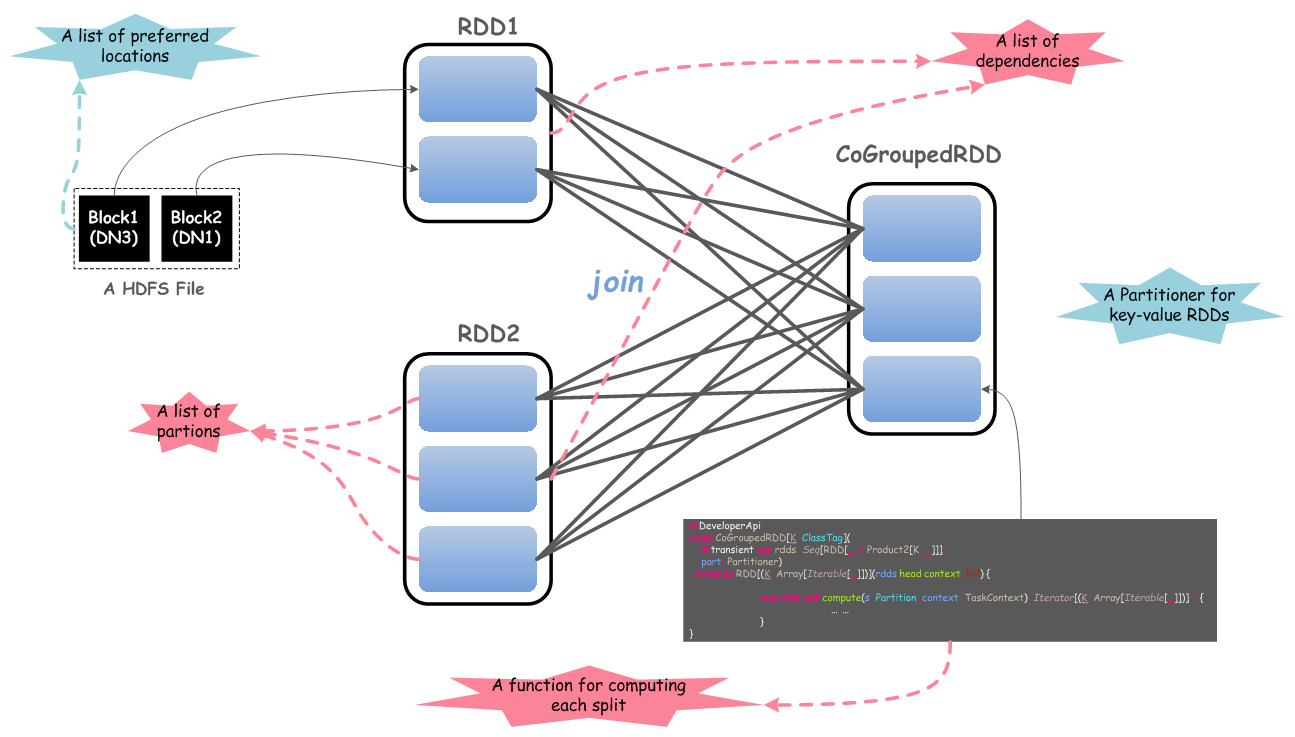 每个RDD有5个主要的属性:
每个RDD有5个主要的属性:
- 一组分片(partition),即数据集的基本组成单位;
- 一个计算每个分片的函数;
- RDD之间的依赖关系;
- 一个Partitioner(分片函数),这是可选择的
- 一个列表,存储存取每个partition的优先位置(preferred location),这是可选择的。
RDD是只读的。
创建RDD的方式:
- 基于物理存储中的数据,比如说磁盘上的文件;
- 通过其他RDD经过Transformation(转换算子)来创建。
RDD是Spark的核心,也是整个Spark的架构基础,可以总结出几个它的特性来:
- 它是不变的数据结构存储
- 它是支持跨集群的分布式数据结构
- 可以根据数据记录的key对结构进行分区
- 提供了粗粒度的操作,且这些操作都支持分区
- 它将数据存储在内存中,从而提供了低延迟性
3.7 RDD narrow/wide dependences
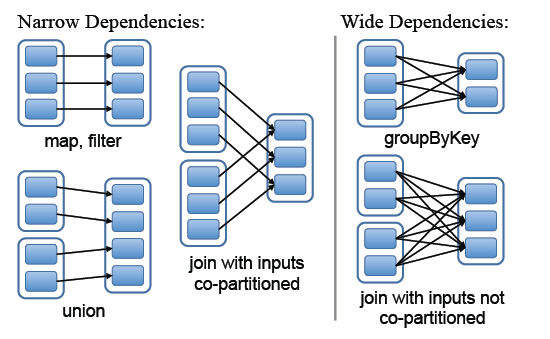
Spark中RDD的粗粒度操作,每一次Transformation都会生成一个新的RDD,这样就会建立RDD之间的前后依赖关系,在Spark中,依赖关系被定义为两种类型,分别是窄依赖和宽依赖
- 窄依赖,父RDD的分区最多只会被子RDD的一个分区使用,即为 OneToOneDependecies;
- 宽依赖,父RDD的一个分区会被子RDD的多个分区使用,即为 OneToManyDependecies。
3.8 Executor
在每个Worker Node上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor。Executor是一个执行Task的容器。每个Application拥有独立的一组Executor。它的主要职责是:
- 初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。
- 同时还有一个ExecutorBackend向Drive Program汇报当前的任务状态,这一方面有点类似hadoop的tasktracker和task。
总结:Executor 是一个应用程序运行的监控和执行容器。
3.9 Job
一个job,就是由一个RDD的Action(行动算子)触发的动作(Action算子触发SparkContext提交Job作业),可以简单的理解为,当你需要执行一个RDD的Action的时候,会生成一个Job。
3.10 Stage
Stage是一个Job的组成单位,就是说,一个job会被切分成1个或1个以上的Stage,然后各个Stage会按照执行顺序依次执行。
Stage的划分方式:
调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到ShuffleDependency(宽依赖关系)就断开,遇到NarrowDependency(窄依赖)就将其加入到当前stage。从触发action操作的RDD往前倒推,如果发现了某个RDD是宽依赖,那么就会将宽依赖的RDD创建为一个新的stage。那个RDD是新的stage中最后一个RDD,这样依次遍历,直到所有的RDD全部遍历。
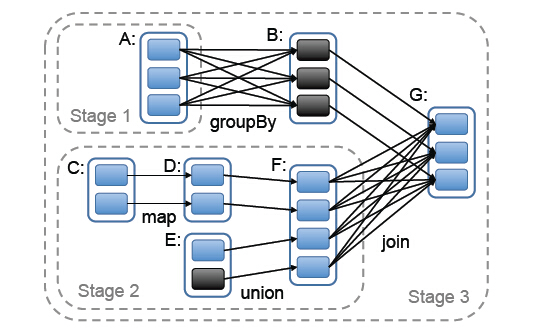
Stage包括两类:ShuffleMapStage和ResultStage,如果用户程序中调用了需要进行Shuffle计算的Operator,如groupByKey等,就会以Shuffle为边界分成ShuffleMapStage和ResultStage。
3.11 TaskSet
基于Stage可以直接映射为TaskSet,一个TaskSet封装了一次需要运算的、具有相同处理逻辑的Task,这些Task可以并行计算,粗粒度的调度是以TaskSet为单位的。
3.12 Task
下发给executor的工作单元。Task包含两类:ShuffleMapTask和ResultTask,分别对应于Stage中ShuffleMapStage和ResultStage中的一个执行基本单元。
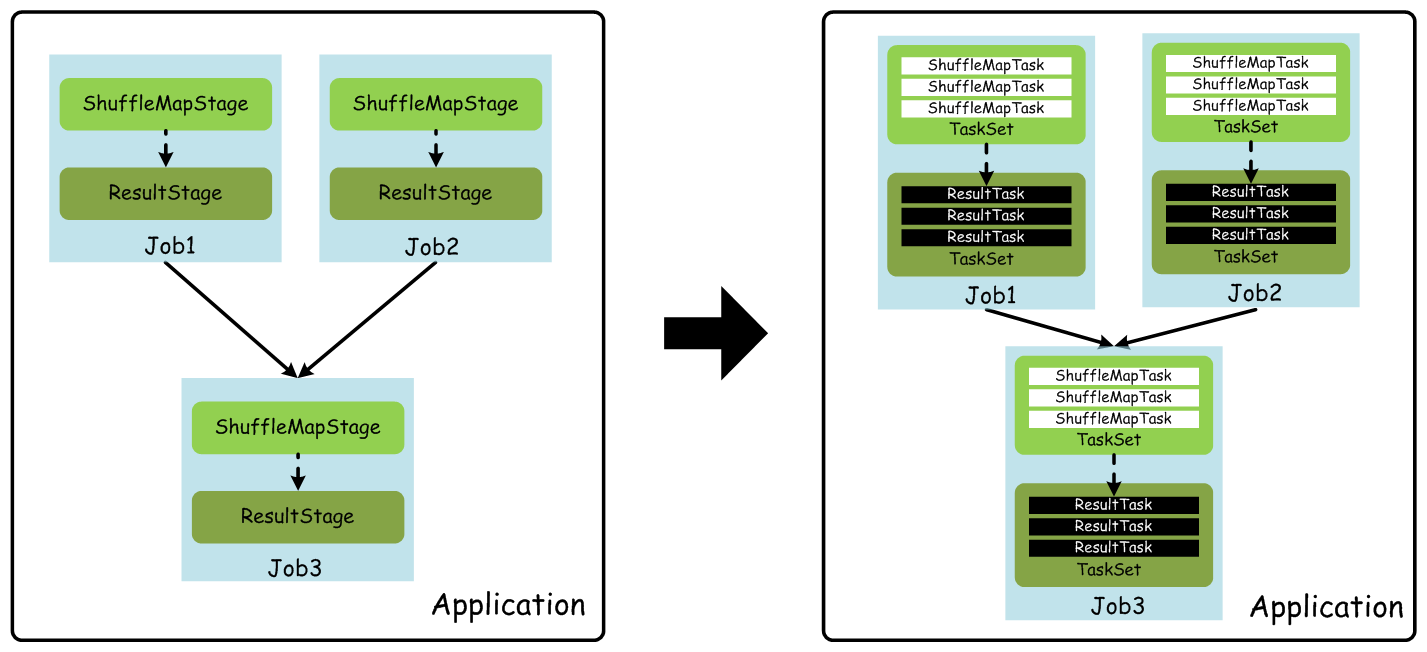
3.13 Partition
Partition的数量决定了task的数量,影响着程序的并行度。
Partition类似Hadoop的Split,计算是以Partition为单位进行的,当然partition的划分依据有很多,这是可以自己定义的,像HDFS文件,划分的方式就和MapReduce一样,以文件的block来划分不同的partition。总而言之,Spark的partition在概念上与Hadoop中的split是相似的,提供了一种划分数据的方式。
参考文献
『 Spark 』2. spark 基本概念解析
《Spark官方文档》集群模式概览
『 Spark 』6. 深入研究 spark 运行原理之 job, stage, task
spark中job运行过程详解和job,stage,task解析
Spark Standalone架构设计要点分析