Kafka基础架构
Kafka是一种分布式的,基于发布/订阅的消息系统。主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输
- 同时支持离线数据处理和实时数据处理
1 基础概念
1.1 发布/订阅的消息机制
消息(message) 的 发送者(publisher) 不直接把消息发送给接收者,它只是以某种方式将消息分类,而 接收者(subscriber) 订阅特定类型的消息。发布/订阅系统通常有一个 中间代理(broker) 作为中间节点来协调这个过程。
1.2 消息
Kafka的内部数据单元称为消息,消息类似于数据库中的一行或者一条记录。消息只是一个字节数组。另外,每个消息都有一个可选的元数据(metadata),称为键值(key),同样键值也是一个字节数组。当消息被写到分区(partition)时,消息的键值可以控制这个分派的过程。最简单的做法是对这个键值进行哈希,把得到的哈希值对分区数量进行取模,来决定消息分派到哪个分区。这样可以保证拥有相同键值的消息可以被写入同一个分区。
1.3 批量提交
为了更高效,消息以批量提交的方式来写入Kafka。批量提交的消息是经过压缩的。这些批量的消息都拥有相同的主题(topic)和分区(Partition)。
1.4 数据的结构
虽然对于Kafka来说消息只是字节数组,但是在实践中,我们建议消息内容是具有格式的,这样可以更容易解析。可选的消息格式有很多,譬如JSON、XML或者Apache Avro。
1.5 主题(topic)与分区(partition)
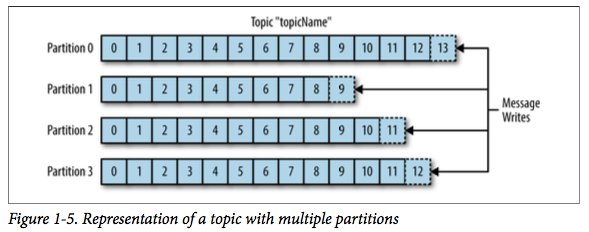
消息以主题(topic)来分类,主题的概念类似于数据库的表。主题可以分成多个分区(partition),一个分区对应于一个单独的日志。消息不断追加到日志的末尾,在读取时从头到尾按序读取。一个主题通常有几个分区,分区内部有序,但分区相互之间不保证顺序。分区可以分布在不同的机器上。
1.6 生产者(producer)
生产者(也称为发布者)创建消息,通常来说生产者不关心消息被写入到哪个分区,在默认情况下Kafka会将消息均衡分配到所有的分区。我们也可以通过消息键值和分配器(partitioner) 来控制消息的分配,分配器会对键值进行哈希并将消息分配到特定分区,这保证了拥有相同键值的消息会被分配到相同的分区。我们也可以自定义分配器,使用特定的业务策略来将消息映射到分区。
1.7 消费者(consumer)
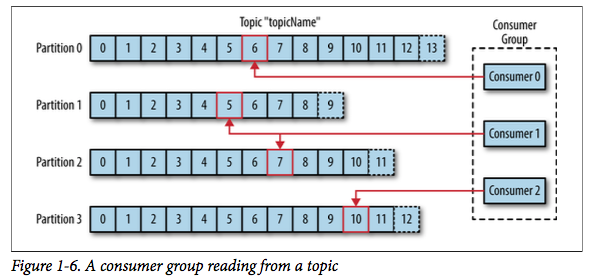
消费者(也称为订阅者)读取消息,通常订阅一个或多个主题。在读取时,消费者记录当前已经读取的消息位移(offset)。位移是一个持续增长的整数值,分区内部的每个消息具有唯一的位移值。通过记录每个分区的已读取消息的位移(可以在Zookeeper或者Kafka内部记录),消费者可以停止或者重启而不丢失消费位置。
消费者以消费组(consumer group)来工作,消费组包含一个或多个消费者。同一topic的一个分区只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
1.8 broker和集群
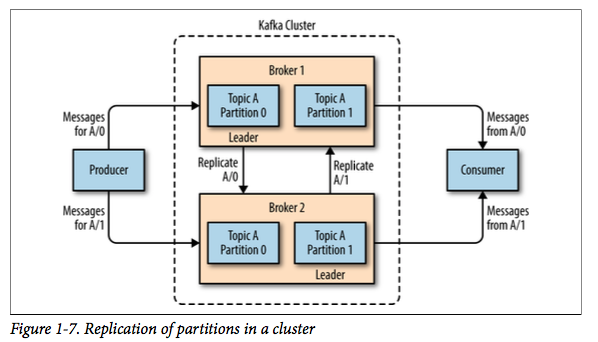
一个Kafka服务器也称为broker。broker接收生产者的消息并赋予其位移值,然后写入到磁盘;broker同时服务消费者拉取分区消息的请求,返回目前已经提交的消息。
若干个broker组成一个集群(cluster),其中集群内某个broker会成为集群控制器(cluster controller),它负责管理集群,包括分配分区到broker、监控broker故障等。在集群内,一个分区由一个broker负责,这个broker也称为这个分区的leader;当然一个分区可以被复制到多个broker上来实现冗余,这样当存在broker故障时可以将其分区重新分配到其他broker来负责。
Kafka的一个关键性质是日志保留(retention),我们可以配置主题的消息保留策略,譬如只保留一段时间的日志或者只保留特定大小的日志。当超过这些限制时,老的消息会被删除。
参考文献
Kafka深度解析
Apache kafka 工作原理介绍
Kafka系列(一)初识Kafka
kafka-Introduction