Hive文件存储格式
2019-02-10
1 列存储和行存储
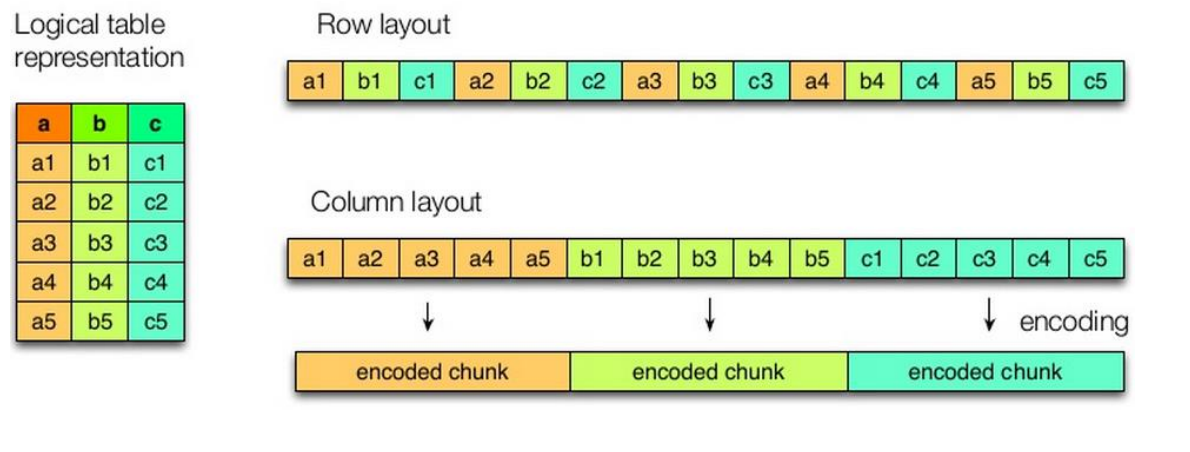
- 行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
- 优点:
- 相关的数据是保存在一起,比较符合面向对象的思维,因为一行数据就是一条记录;
- 这种存储格式比较方便进行INSERT/UPDATE操作。
- 缺点:
- 如果查询只涉及某几个列,它会把整行数据都读取出来,不能跳过不必要的列读取。当然数据比较少,一般没啥问题,如果数据量比较大就比较影响性能;
- 由于每一行中,列的数据类型不一致,导致不容易获得一个极高的压缩比,也就是空间利用率不高;
- 不是所有的列都适合作为索引。
- 优点:
- 列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的压缩算法。
- 优点:
- 查询时,只有涉及到的列才会被查询,不会把所有列都查询出来,即可以跳过不必要的列查询;
- 高效的压缩率,不仅节省储存空间也节省计算内存和CPU;
- 任何列都可以作为索引。
- 缺点:
- INSERT/UPDATE很麻烦或者不方便;
- 不适合扫描小量的数据。
- 优点:
2 Hive中常用的存储格式
- textfile:textfile为默认格式,存储方式为行存储。
- ORCFile:hive/spark都支持这种存储格式,它存储的方式是采用数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。特点是数据压缩率非常高。使用ORC文件格式可以提高hive读、写和处理数据的能力。
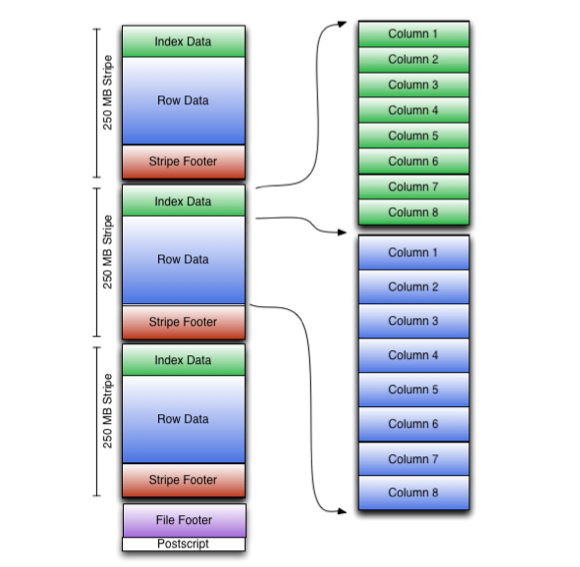
每个ORC文件由1个或多个stripe组成,每个stripe为250MB大小,每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer。- Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset,还包括每个Column的max和min值所在的行。
- Row Data:存的是具体的数据,和RCfile一样,先取部分行,然后对这些行按列进行存储。与RCfile不同的地方在于每个列进行了编码,分成多个Stream来存储。
- Stripe Footer:存的是各个Stream的类型,长度等信息。
- Parquet:Parquet也是一种列式存储格式,具有很好的压缩性能;可以减少大量的表扫描和反序列化的时间。
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;ORCFILE,Parquet格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从表中用insert导入ORCFile,Parquet表中。
3 总结
- textfile:存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高。
- ORCFile:存储空间最小,查询的最高,需要通过text文件转化来加载,加载的速度最低。