Hive基础架构
Hive 是基于 Hadoop 构建的一套数据仓库分析系统,它提供了丰富的 SQL 查询方式来分析存储在 Hadoop 分布式文件系统中的数据, 可以将结构化的数据文件映射为一张数据库表,并提供简单的类SQL(称为HQL)查询功能,可以将HQL语句转换为MapReduce任务进行运行。
Hive与传统关系数据库比较有如下几个特点:
- 侧重于分析,而非实时在线交易
- 无事务机制
- 不像关系数据库那样可以随机进行 insert或update.
- 通过Hadoop的map/reduce进行分布式处理,传统数据库则没有
- 传统关系数据库只能拓展最多20个服务器,而Hive可以拓展到上百个服务器。
1 Hive架构
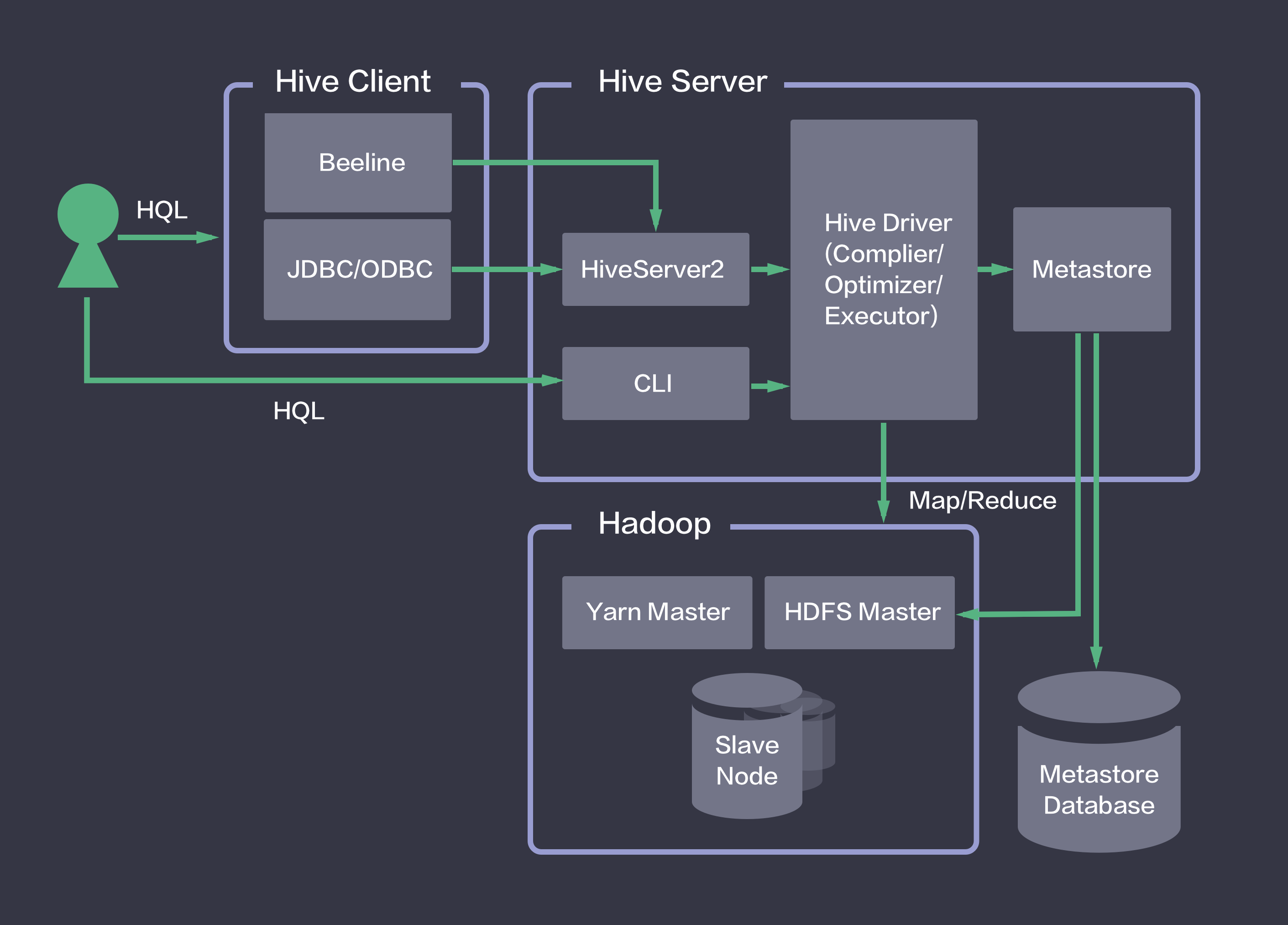
Hive就是在Hadoop上架了一层HQL接口,可以将HQL语句翻译成MapReduce去Hadoop上执行。同时,Hive将元数据存储在关系数据库中,用Metastore服务实现元数据管理。 用户在Hive Client端发起HQL任务,通过Hive Server实现HQL到Map Reduce任务的转换,然后调用Hadoop集群执行。
Hive 的结构可以分为以下几部分:
- 用户接口:主要有三个:CIL(命令行),JDBC/ODBC(java),WebUI(浏览器访问)。
- Metastore:是系统目录,保存Hive中表的元数据信息。metastore包含:
- Database是表(table)的名字空间。默认的数据库(database)名为‘default’
- Table表的元数据,包含信息有:列(list of columns)和它们的类型(types),拥有者(owner),存储空间(storage)和SerDei信息
- Partition每个分区(partition)都有自己的列(columns),SerDe和存储空间(storage)。这一特征将被用来支持Hive中的模式演变(schema evolution)
- 元数据存储:元数据包括Hive的用户信息与表的MetaData。通常是存储在关系数据库中,默认存储在自带的derby数据库中,推荐使用采用MySQL存储Metastore。
- 内嵌模式:存储在内嵌的数据库Derby
- 多用户模式:存储在本地MySQL
- 远程模式:存储在远程的MySQL
内置的derby主要问题是并发性能很差,可以理解为单线程操作。MySQL可以多用户同时访问。
- Driver(解析器、编译器、优化器、执行器):完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
- Hadoop:用 HDFS 进行存储,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
- HiveServer2:是一个能使客户端针对hive执行查询的一种服务,允许远程客户端使用多种语言诸如Java,Python等向Hive提交请求,然后取回结果。与HiverServer1比较,它能够支持多个客户端的并发请求和授权的。
2 Hive数据模型
- Databases:数据库。概念等同于关系型数据库的Schema;
- Tables:表。概念等同于关系型数据库的表;
- Partitions:分区。概念类似于关系型数据库的表分区,只支持固定分区,将同一组数据存放至一个固定的分区中。
- Buckets (or Clusters):分桶。同一个分区内的数据还可以细分,将相同的KEY再划分至一个桶中,这个有点类似于HASH分区,只不过这里是HASH分桶,也有点类似子分区吧。
Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/apps/hive/warehouse</value>
</property>
Hive数据表有五种类型:内部表,外部表,分区表,桶表,视图表。
2.1 内部表
- 与数据库中的表相似。
- 每一个都有相对应的目录, 存储在hive.metastore.warehouse.dir下,以表名为目录,表的所有数据都在这个目录下。
- 删除表时,元数据与数据都会被删除。
创建一个内部表,和mysql创建表基本一致,默认表存储在hive.metastore.warehouse.dir。可以通过location指定表的存储位置。在建表的时候可以设置分割符, 默认存储按照制表符分割。
-- 创建内部表
create table t1(
id int,
name string,
age int);
-- 指定内部表位于hdfs中的位置
create table t2(
id int,
name string,
age int)
location '/mytable/hive/t2';
-- 设置分割符
create table t3(
id int,
name string,
age int)
row format delimited fields terminated by ',';
2.2 外部表
- 其数据不是放在自己表所属的目录中,而是存放到别处,如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;
- 可以创建Partition
- 它和内部表在元数据的组织上时相同的,而实际存储则有极大的差异
- 外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只会与外部数据创建一个链接,当删除该表时,仅删除该链接而不删除实际的数据
创建外部表,使用关键字external, 指定分隔符,表的创建,与数据加载同时发生,所以使用location指定数据的存储位置。 并不会移动到数据仓库目录中,只是与外部数据建立一个链接,当删除一个外部表时,只会删除该链接,但是输出外部数据,外部表就会减少数据(实际上当你查看文件你会发现数据还在)。
create external table ext_table(
id string,
name string)
row format delimited fields terminated by ','
location '/input/hive/';
2.3 分区表
- Partition对应于数据库Partiton列的密集索引。
- 在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。
在创建表时候,使用PARTITIONED BY关键字来指定该表为分区表,后面括号中指定了分区的字段和类型,分区字段可以有多个,在HDFS中对应多级目录。将数据组织成分区,主要可以提高数据的查询速度。可以对分区进行增加、插入、修复和删除。其中删除分区就会删除该分区的文件夹以及其中的数据,同内部表和外部表,如果该分区表为外部表,则分区对应的HDFS目录数据不会被删除。
-- 创建分区
create table patition_table(
id int,
name string)
partitioned by (gender string)
row format delimited fields terminated by ',';
-- 增加分区
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location'][, PARTITION partition_spec [LOCATION 'location'], ...];
partition_spec:
: (partition_column = partition_col_value, partition_column = partition_col_value, ...)
-- 增加相同分区字段
ALTER TABLE page_view ADD PARTITION (dt='2008-08-08', country='us') location '/path/to/us/part080808'
PARTITION (dt='2008-08-09', country='us') location '/path/to/us/part080809';
-- 增加不同分区字段
alter table idc_20180315 add if not exists partition(dt='20180315', hour='11') location '20180315/11';
-- 往分区中追加数据
INSERT INTO TABLE t_lxw1234 PARTITION (month = ‘2015-06′,day = ‘2015-06-15′) SELECT * FROM dual;
-- 覆盖分区数据
INSERT overwrite TABLE t_lxw1234 PARTITION (month = ‘2015-06′,day = ‘2015-06-15′) SELECT * FROM dual;
-- 删除分区字段
alter table testljb drop partition(age=1);
-- 修复分区(重新同步hdfs上的分区信息)
msck repair table table_name;
-- 查看分区对应的HDFS路径
show partitions table_name;
hive提供两种分区表:静态分区和动态分区。两者主要的差别在于:加载数据的时候,动态分区不需要指定分区key的值,会根据key对应列的值自动分区写入,如果该列值对应的分区目录还没有创建,会自动创建并写入数据。
配置动态分区:
// 是否开启动态分区功能,默认false关闭。
set hive.exec.dynamic.partition=true;
// 动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。
set hive.exec.dynamic.partition.mode=nonstrict;
// 在每个执行MR的节点上,最大可以创建多少个动态分区。默认值:100
set hive.exec.max.dynamic.partitions.pernode=100
// 在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认值:1000
set hive.exec.max.dynamic.partitions=1000
// 整个MR Job中,最大可以创建多少个HDFS文件。默认值:100000
set hive.exec.max.created.files=100000
// 当有空分区生成时,是否抛出异常。默认值:false
set hive.error.on.empty.partition=false
例如:
CREATE TABLE t_lxw1234_partitioned (
url STRING
) PARTITIONED BY (month STRING,day STRING)
stored AS textfile;
-- 将t_lxw1234中的数据按照时间(day),插入到目标表t_lxw1234_partitioned的相应分区中。
-- 先设置
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions.pernode = 1000;
SET hive.exec.max.dynamic.partitions=1000;
-- 插入操作
INSERT overwrite TABLE t_lxw1234_partitioned PARTITION (month,day)
SELECT url,substr(day,1,7) AS month,day
FROM t_lxw1234;
注意:在PARTITION(month,day)中指定分区字段名即可;在SELECT子句的最后两个字段,必须对应前面PARTITION(month,day)中指定的分区字段,包括顺序。在一个表同时使用动态和静态分区表时,静态分区值必须在动态分区值的前面。
尽量让分区列的值相同的数据在同一个 MapReduce 中,这样每一个 MapReduce 可以尽量少地产生新的文件夹,可以通过DISTRIBUTE BY将分区列值相同的数据放到一起,命令如下。
insert overwrite table partition_test
partition(stat_date,province)
select memeber_id,name,stat_date,province
from partition_test_input
distribute by stat_date,province;
2.4 桶表
Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。桶表中的数据,是通过哈希运算后,将其打散,再存入文件当中,这样做会避免造成热块,从而提高查询速度。
我们使用CLUSTERED BY子句来指定划分桶所用的列和要划分的桶的个数,桶中的数据可以根据一个或多个列进行排序。
CREATE TABLE bucketed_users(id INT, name STRING) CLUSTERED BY (id) SORTED BY (id ASC) INTO 4 BUCKETS
2.5 视图
- 只有逻辑视图不存储数据的,可以跨越多张表,没有物化视图;
- 视图只能查询,不能Load/Insert/Update/Delete数据;
- 视图在创建时候,只是保存了一份元数据,当查询视图的时候,才开始执行视图对应的那些子查询;
-- 创建视图
create view ... as ...
-- 删除视图
drop view ...
-- 修改视图
alter view ...
3 Hive数据类型
3.1 原始数据类型
整型、布尔型、浮点型、Date、时间戳和字符串型等
3.2 复合数据类型
- Struct:一组由任意数据类型组成的结构。比如,定义一个字段C的类型为STRUCT {a INT; b STRING},则可以使用C.a和C.b来获取其中的元素值;
- Map:和Java中的Map没什么区别,就是存储K-V对的;
- Array:就是数组,Array类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问;
- Union:Hive除了支持STRUCT、ARRAY、MAP这些原生集合类型,还支持集合的组合,不支持集合里再组合多个集合。
参考文献
hive数据模型
[一起学Hive]之三–Hive中的数据库(Database)和表(Table)
[一起学Hive]之一–Hive概述,Hive是什么
Hive内置数据类型
[一起学Hive]之六-Hive的动态分区