Hive优化
1 使用分区剪裁、列剪裁
在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT * 。
2 少用COUNT DISTINCT
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换。
3 是否存在多对多的关联
只要遇到表关联,就必须得调研一下,是否存在多对多的关联,起码得保证有一个表或者结果集的关联键不重复。还有就是避免笛卡尔积。
4 JOIN操作
在编写带有 join 操作的代码语句时,应该将条目少的表/子查询放在 Join 操作符的左边。 因为在 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,载入条目较少的表 可以有效减少 OOM(out of memory)即内存溢出。这便是“小表放前”原则。
5 MAP JOIN操作
MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率。前提条件是需要的数据在 Map 的过程中可以访问到。
INSERT OVERWRITE TABLE pv_users
SELECT /*+ MAPJOIN(pv) */ pv.pageid, u.age
FROM page_view pv
JOIN user u ON (pv.userid = u.userid);
注意: Hive0.7之前,需要使用hint提示 /*+ mapjoin(table) */才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true.
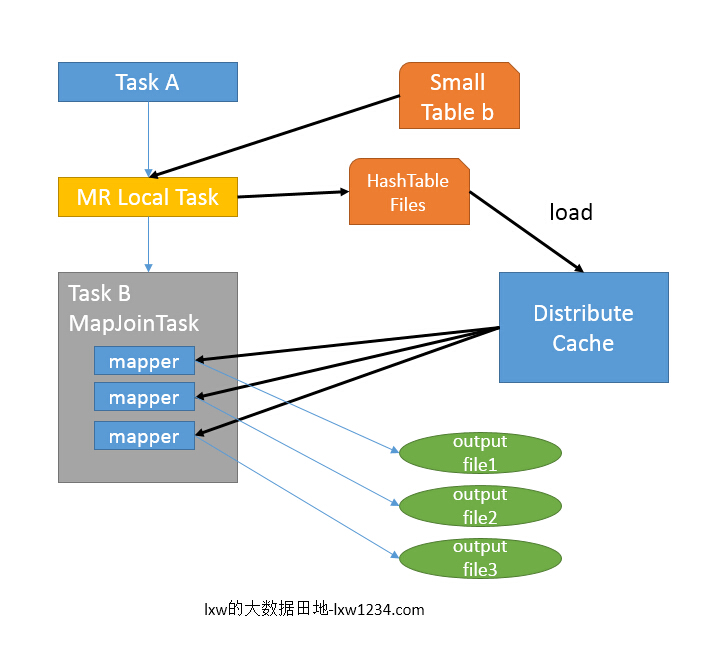
- 如图中的流程,首先是Task A,它是一个Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构(<kety,value>),并写入本地的文件中,之后将该文件加载到DistributeCache中。
- 接下来是Task B,该任务是一个没有Reduce的MR,启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果。
- 由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个Map Task,就有多少个结果文件。
6 GROUP BY操作
- Map端部分聚合:
hive.map.aggr=true(用于设定是否在 map 端进行聚合,默认值为真) - 有数据倾斜时进行负载均衡:
hive.groupby.skewindata=true。
7 合并小文件
- 是否合并Map输出文件:
hive.merge.mapfiles=true(默认值为真) - 是否合并Reduce 端输出文件:
hive.merge.mapredfiles=false(默认值为假) - 合并文件的大小:
hive.merge.size.per.task=256*1000*1000(默认值为 256000000)
8 合理使用Union All
对同一张表的union all 要比multi insert快的多。
9 避免数据倾斜
10 控制map/reduce任务数量
11 压缩数据
对数据进行压缩不仅可以减少数据的大小,还可以节省磁盘的读写时间。在Hive查询中,可以对中间数据和最终结果数据进行压缩。
参考文献
[一起学Hive]之十二-Hive SQL的优化
Hive性能优化
Hive MapJoin
Hive性能优化小结
hive 查询性能优化总结
[一起学Hive]之十-Hive中Join的原理和机制
hive的MapJoin机制