Hadoop中Shuffle过程
在进行分布式计算的时候,Shuffle过程分别发生在Map和Reduce阶段,本文将细致分析Shuffle过程中设计到的多个操作。
1 MapReduce计算模型
MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce。
- Map:数据输入,做初步的处理,输出形式的中间结果;
- Shuffle:按照partition、key对中间结果进行排序合并,输出给reduce线程;
- Reduce:对相同key的输入进行最终的处理,并将结果写入到文件中。
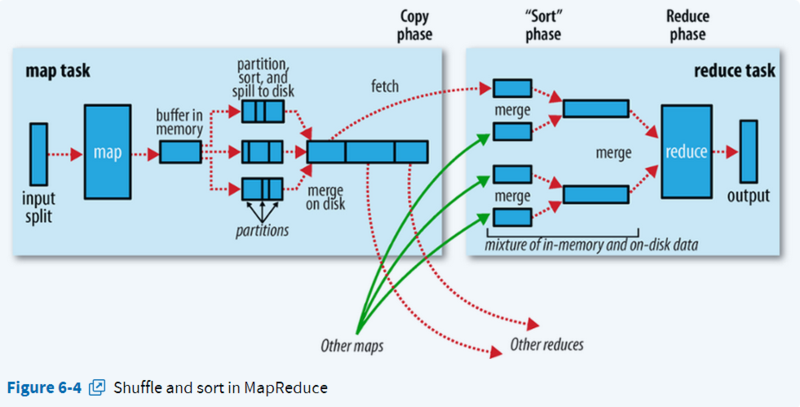
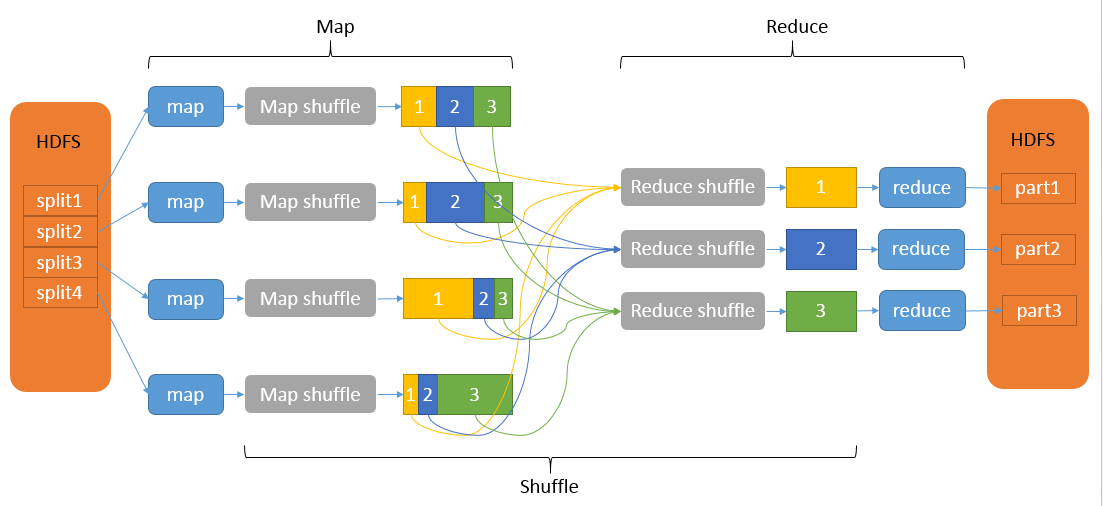
Map和Reduce操作需要我们自己定义相应Map类和Reduce类,以完成我们所需要的化简、合并操作,而shuffle则是系统自动帮我们实现的。Shuffle过程有一部分是在Map端,有一部分是在Reduce端。
2 Shuffle
Shuffle过程中的几个名词:Shuffle:洗牌;spill:溢出;combiner:合成;merge:融入混合;copy:复制。
Shuffle的使用地点:发生在map task输出结果传送到reduce task 输入的阶段。
使用Shuffle的好处:
- 在从map task端拉取数据到reduce task端时,减少宽带的消耗;
- 将数据完整的从map task端拉取数据到reduce task端;
- 减少磁盘IO对task的影响。
2.1 执行过程
2.1.1 map端
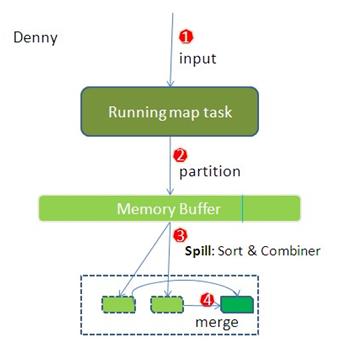
2.1.1.1 Partioner
在执行完map后,map的输出是k/v对。需要给reduce task处理,这里就需要使用Partioner为k/v指定处理它的reduce,总的Partioner的数目等于reducer的数量。
- 作用:将map的结果发送到相应的reduce端。
- 实现功能:
- map输出的是key/value对,决定于当前的mapper的part交给哪个reduce的方法是:mapreduce提供的Partitioner接口,对key进行hash后,再以reduce task数量取模,然后到指定的reduce task上(HashPartitioner,可以通过
job.setPartitionerClass(MyPartition.class)自定义)。 - 然后将数据写入到内存缓冲区,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。key/value对以及Partition的结果都会被写入缓冲区。在写入之前,key与value值都会被序列化成字节数组。
- map输出的是key/value对,决定于当前的mapper的part交给哪个reduce的方法是:mapreduce提供的Partitioner接口,对key进行hash后,再以reduce task数量取模,然后到指定的reduce task上(HashPartitioner,可以通过
- 要求:负载均衡,效率;
2.1.1.2 spill(溢写):sort & combiner
在map task端将输出的数据写入缓冲区直到到达阈值(默认缓冲区大小100M,阈值是80%)。达到阈值启动溢写线程(spill)。
- 作用:把内存缓冲区中的数据写入到本地磁盘,在写入本地磁盘时先按照partition、再按照key进行排序(quick sort);
- 注意:
- 这个spill是由另外单独的线程来完成,不影响往缓冲区写map结果的线程;
- 内存缓冲区默认大小限制为100MB,它有个溢写比例(
spill.percent),默认为0.8,当缓冲区的数据达到阈值时,溢写线程就会启动,先锁定这80MB的内存,执行溢写过程,maptask的输出结果还可以往剩下的20MB内存中写,互不影响。然后再重新利用这块缓冲区,因此Map的内存缓冲区又叫做环形缓冲区; - 在将数据写入磁盘之前,先要对要写入磁盘的数据进行一次排序操作,先按
<key,value,partition>中的partition分区号排序,然后再按key排序,这个就是sort操作,最后溢出的小文件是分区的,且同一个分区内是保证key有序的;
combiner:执行combiner操作要求开发者必须在程序中设置了combine(程序中通过job.setCombinerClass(myCombine.class)自定义combine操作)。Combiner本身是一个reduce操作。combiner是个优化过程,这样可以减少map和reduce任务之间传输的中间数据,减少partition的索引记录。
- 程序中有两个阶段可能会执行combine操作:
- map输出数据根据分区排序完成后,在写入文件之前会执行一次combine操作(前提是作业中设置了这个操作);
- 如果map输出比较大,溢出文件个数大于3(此值可以通过属性
min.num.spills.for.combine配置)时,在merge的过程(多个spill文件合并为一个大文件)中还会执行combine操作;
- combine主要是把形如
<aa,1>,<aa,2>这样的key值相同的数据进行计算,计算规则与reduce一致,比如:当前计算是求key对应的值求和,则combine操作后得到<aa,3>这样的结果。 - combiner和reduce的区别:combiner操作发生在map端,处理一个任务所接收的文件中的数据,不能跨map任务执行;只有reduce可以接收多个map任务处理的数据
2.1.1.3 merge
- merge过程:如果数据很大,会发生多次溢写既会有多个溢写文件,待Map Task任务的所有数据都处理完后,会对任务产生的所有中间数据文件做一次合并操作,以确保一个Map Task最终只生成一个中间数据文件。
- 注意:
- 如果生成的文件太多,可能会执行多次合并,每次最多能合并的文件数默认为10,可以通过属性
min.num.spills.for.combine配置; - 多个溢出文件合并时,会进行一次排序,排序算法是多路归并排序;
- 是否还需要做combine操作,一是看是否设置了combine,二是看溢出的文件数是否大于等于3;
- 最终生成的文件格式与单个溢出文件一致,也是按分区顺序存储,并且输出文件会有一个对应的索引文件,记录每个分区数据的起始位置,长度以及压缩长度,这个索引文件名叫做
file.out.index。
- 如果生成的文件太多,可能会执行多次合并,每次最多能合并的文件数默认为10,可以通过属性
到此map端工作结束,生成的这个文件存放在taskTracker能拿到的某个本地目录内,每个reduce task不断地通过RCP从JobTacker那获取map task是否完成。如果reduce task 得到通知获知某台TaskTrack上的map task执行完成,shuffle开始执行将map的输出拉入reduce过程。 rudecer真正执行之前就是不断的拉取当前job里的每个map输出结果然后不断的merge,最终形成一个文件作为reduce task的输入文件。
2.1.2 reduce端
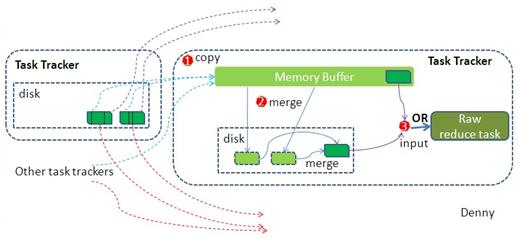
2.1.2.1 copy
拉取数据,reduce进程启动一些数据copy线程(Fetcher),通过http方式请求map task所在的TaskTrack 获取map task输出文件(文件被TaskTracker管理在本地磁盘),copy一份属于自己的数据。这些copy的数据会首先保存的内存缓冲区中,当内冲缓冲区的使用率达到一定阀值后,则写到磁盘上。
2.1.2.2 merge
这里使用的Merge和Map端使用的Merge过程一样。Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边merge一边sort,即merge和sort两个阶段是重叠而不是完全分开的。
merge有三种方式:内存到内存、内存到磁盘和磁盘到磁盘,默认不启用第一种。
- 内存到磁盘:当内存中的数据量到达一定阈值,就启动内存到磁盘的 merge(图中的第一个merge,之所以进行merge是因为reduce端在从多个map端copy数据把它们加载到内存,当达到阈值写入磁盘时,需要进行merge)。这和map端的很类似,这实际上就是溢写的过程,如果设置combiner,它也会启用,然后在磁盘生成很多溢写文件,直到map端没有数据,第二种merge方式结束。
- 磁盘到磁盘:启用第三种方式merge(图中第二个merge)生成最终的那个文件。
2.1.2.3 reduce的输入文件
merge的最后会生成一个文件,大多数情况下存在于磁盘中,但是需要将其放入内存中。当reducer 输入文件已定,整个 Shuffle 阶段才算结束。然后就是 Reducer 执行,把结果放到 HDFS 上。
参考文献
详解MapReduce中shuffle过程
MapReduce之Shuffle过程详述
MapReduce shuffle过程详解
Hadoop学习笔记—10.Shuffle过程那点事儿