HBase基础架构
什么是HBase?HBase有什么特点?HBase的数据模型是什么?等等,这些问题都将被一一解答。
1 HBase是什么
HBase 是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群。
HBase 利用Hadoop HDFS 作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为其分布式协同服务。主要用来存储非结构化和半结构化的松散数据(列存NoSQL数据库)。
2 HBase的特点
- 强一致性读写: HBase 不是 “最终一致性(eventually consistent)” 数据存储. 这让它很适合高速计数聚合类任务。
- 自动分片(Automatic sharding): HBase 表通过region分布在集群中。数据增长时,region会自动分割并重新分布。
- RegionServer 自动故障转移
- 大:一个表可以有上亿行,上百万列。
- 面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
- 稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
- 数据类型单一:Hbase中的数据都是字符串,没有类型。
3 HBase的数据模型
3.1 概念视图

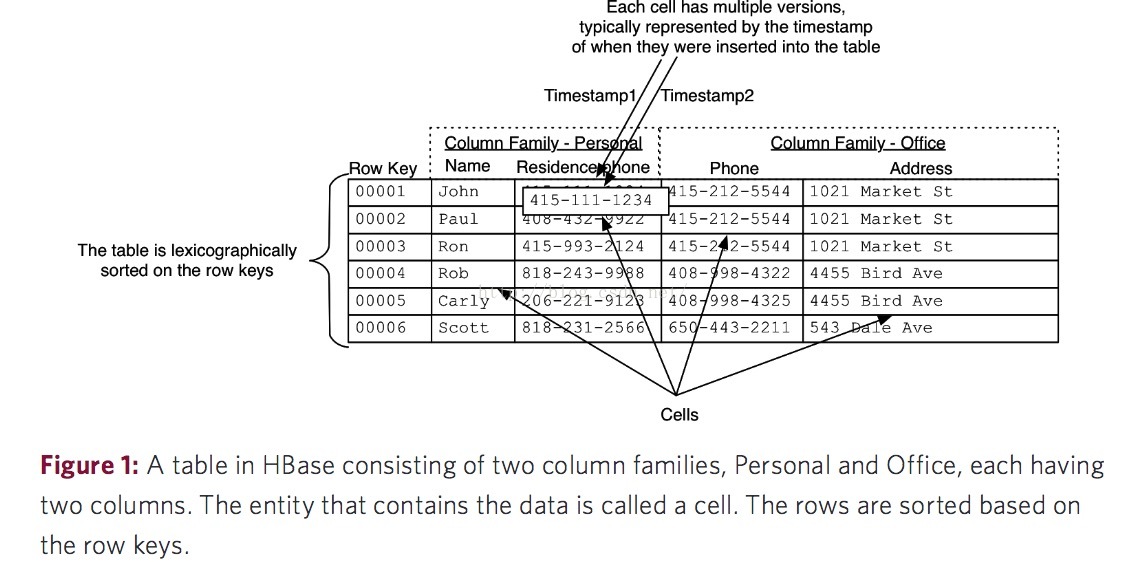
HBase的数据模型也是由一张张的表组成,每一张表里也有数据行和列。下面统一介绍HBase数据模型中一些名词的概念:
- 表(Table):HBase会将数据组织进一张张的表里面,但是需要注意的是表名必须是能用在文件路径里的合法名字,因为HBase的表是映射成hdfs上面的文件。
- 行(Row):在表里面,每一行代表着一个数据对象,每一行都是以一个行键(Row Key)来进行唯一标识的,行键并没有什么特定的数据类型,以二进制的字节来存储。行是按字典排序由低到高存储在表中的。
- 列族(Column Family):在定义HBase表的时候需要提前设置好列族, 表中所有的列都需要组织在列族里面,列族一旦确定后,就不能轻易修改,因为它会影响到HBase真实的物理存储结构,但是列族中的列标识(Column Qualifier)以及其对应的值可以动态增删。表中的每一行都有相同的列族,但是不需要每一行的列族里都有一致的列标识(Column Qualifier)和值,所以说是一种稀疏的表结构,这样可以一定程度上避免数据的冗余。例如:{row1, userInfo: telephone —>137XXXXX869 }{row2, userInfo: fax phone —>0898-66XXXX } 行1和行2都有同一个列族userinfo,但是行1中的列族只有列标识(Column Qualifier):移动电话号码,而行2中的列族中只有列标识(Column Qualifier):传真号码。
- 列标识(Column Qualifier):列族中的数据通过列标识来进行映射,其实这里大家可以不用拘泥于“列”这个概念,也可以理解为一个键值对,Column Qualifier就是Key。列标识也没有特定的数据类型,以二进制字节来存储。
- 单元(Cell):每一个行键,列族和列标识共同组成一个单元,存储在单元里的数据称为单元数据,单元和单元数据也没有特定的数据类型,以二进制字节来存储。
- 时间戳(Timestamp):默认下每一个单元中的数据插入时都会用时间戳来进行版本标识。读取单元数据时,如果时间戳没有被指定,则默认返回最新的数据,写入新的单元数据时,如果没有设置时间戳,默认使用当前时间。每一个列族的单元数据的版本数量都被HBase单独维护,默认情况下HBase保留3个版本数据。
3.2 物理视图
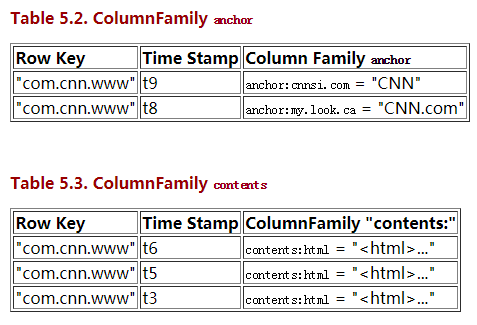
尽管在概念视图里,表可以被看成是一个稀疏的行的集合。但在物理上,它的是区分列族 存储的。新的columns可以不经过声明直接加入一个列族。
值得注意的是在上面的概念视图中空白cell在物理上是不存储的。因此若一个请求为要获取t8时间的contents:html,他的结果就是空。但是,如果不指明时间,将会返回最新时间的行,每个最新的都会返回。例如,如果请求为获取行键为”com.cnn.www”,没有指明时间戳的话,活动的结果是t6下的contents:html,t9下的anchor:cnnsi.com和t8下anchor:my.look.ca。
- Table中所有行都按照row key的字典序排列;
- Table在行的方向上分割为多个Region;
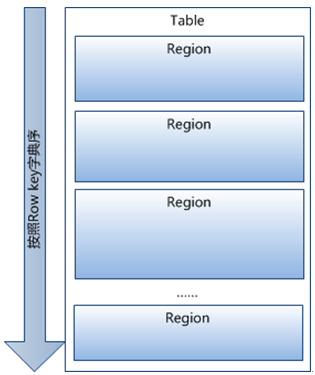
- Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
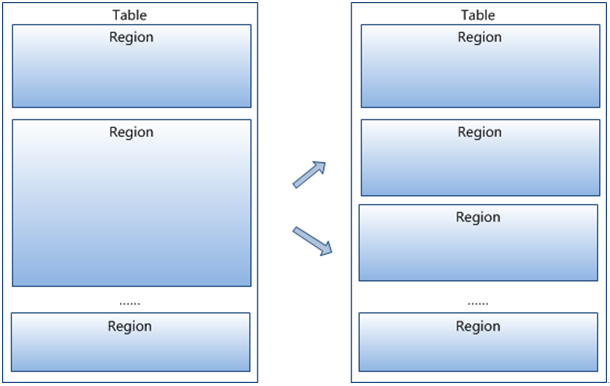
- Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。
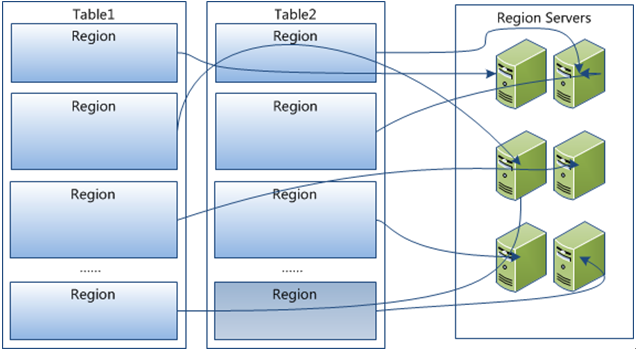
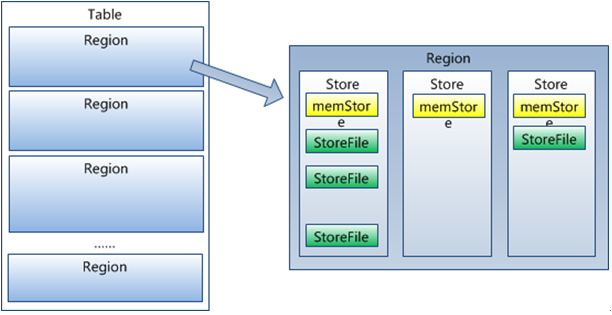
- Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个列族 (Column Family) 创建一个 Store 实例;每个Strore又由一个memStore和0至多个StoreFile组成,每个 StoreFile 都会对应一个 HFile,HFile 就是实际的存储文件;memStore存储在内存中,StoreFile存储在HDFS上。
4 HBase架构及基本组件
Hbase 是一种专门为半结构化数据和水平扩展性设计的数据库。它把数据存储在表中,表按“行健,列簇,列限定符和时间版本”的四维坐标系来组织。Hbase 是无模式数据库,只需要提前定义列簇,并不需要指定列限定符。同时它也是无类型数据库,所有数据都是按二进制字节方式存储的,对 Hbase 的操作和访问有 5 个基本方式,即 Get、Put、Delete 和 Scan 以及 Increment。
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由一下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,总体结构如下:
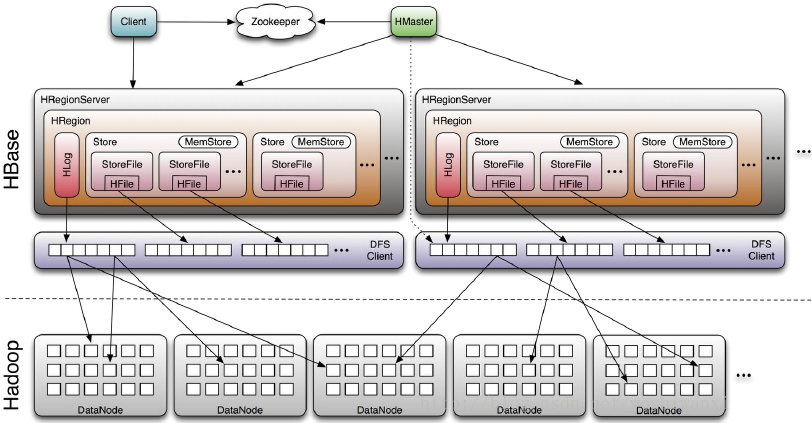
4.1 Client
使用HBase RPC机制与HMaster和HRegionServer进行通信
- Client与HMaster进行通信管理类操作
- Client与HRegionServer进行数据读写类操作
4.2 HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master在运行。主要负责Table和Region的管理工作:
- 管理用户对表的增删改查操作
- 管理HRegionServer,实现其负载均衡
- 管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上
- 管控集群, 监控所有RegionServer的状态
- 权限控制(ACL)
4.3 HRegionServer
- HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写数据,管理Table中的数据。
- HRegionServer内部管理了多个Region,每个Region是由多个HStore组成的,对应着Table中的一个Region。
- Regionserver负责切分在运行过程中变得过大的region。
- 存放和管理本地HRegion。
- Client直接通过HRegionServer读写数据。
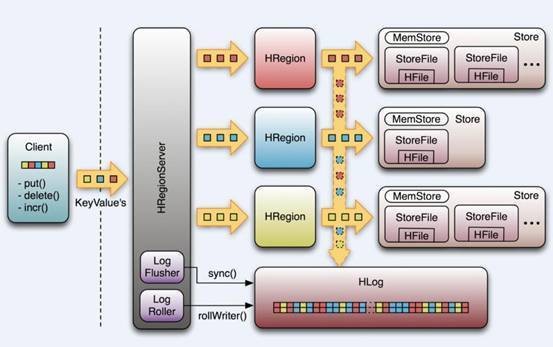
- HRegionServer管理一些列HRegion对象;
- 每个HRegion对应Table中一个Region,HRegion由多个HStore组成;
- 每个HStore对应Table中一个Column Family的存储;
- Column Family就是一个集中的存储单元,故将具有相同IO特性的Column放在一个Column Family会更高效
HBase 中的每张表都通过行键按照一定的范围被分割成多个子表(HRegion),默认一个 HRegion 超过 256M 就要被分割成两个,由 HRegionServer 管理,管理哪些 HRegion 由 HMaster 分配。
HRegionServer 存取一个子表时,会创建一个 HRegion 对象,然后对表的每个列族 (Column Family) 创建一个 Store 实例,每个 Store 都会有 0 个或多个 StoreFile 与之对应,每个 StoreFile 都会对应一个 HFile,HFile 就是实际的存储文件。因此,一个 HRegion 有多少个列族就有多少个 Store。此外,每个 HStore 还拥有一个 MemStore 内存缓存实例。
4.4 HRegion的管理
Region是HBase数据存储和管理的基本单位。Client从.META.表的查找RowKey对应的Region的位置,每个Region只能被一个HRegionServer提供服务,HRegionServer可以同时服务多个Region,来自不同HRegionServer上的Region组合成表格的整体逻辑视图。
4.5 HStore
HBase存储的核心。由MemStore和StoreFile组成。
- MemStore:MemStore 即内存里放着的保存 KEY/VALUE 映射的 MAP,当 MemStore(默认 128MB)写满之后,会开始 flush 到磁盘(即 Hadoop 的 HDFS 上)的操作。
- HFile:HBase 中 KeyValue 数据的存储格式,HFile 是 Hadoop 的二进制格式文件,实际上 StoreFile 就是对 HFile 做了轻量级包装,即 StoreFile 底层就是 HFile。
4.6 ZooKeeper集群
- 通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册
- 存贮所有Region的寻址入口
- 实时监控Region server的上线和下线信息。并实时通知给Master
- 存储HBase的schema和table元数据(包括有哪些table,每个table有哪些column family)
- 默认情况下,HBase 管理ZooKeeper 实例,比如, 启动或者停止ZooKeeper
- Zookeeper的引入使得Master不再是单点故障
4.7 HLog
每个HRegionServer中都会有一个HLog对象,HLog是一个实现Write Ahead Log的类,每次用户操作写入Memstore的同时,也会写一份数据到HLog文件,HLog文件定期会滚动出新,并删除旧的文件(已持久化到StoreFile中的数据)。
5 Region定位
- 第一次读取:
- 读取ZooKeeper中ROOT表的位置。
- 读取ROOT表中.META表的位置。
- 读取.META表中用户表的位置。
- 读取数据。
- 如果已经读取过一次,则root表和.META都会缓存到本地,则直接去用户表的位置读取数据。
6 -ROOT- 表与 .META. 表
6.1 -ROOT- 表
是一张存储.META.表的表,记录了.META.表的Region信息,-ROOT-只有一个region
6.2 .META. 表
是一张元数据表,记录了用户表的Region信息以及RegionServer的服务器地址,.META.可以有多个regoin。.META.表中的一行记录就是一个Region,记录了该Region的起始行、结束行和该Region的连接信息。
7 何时使用Hbase
- 需对数据进行随机读操作或者随机写操作;
- 大数据上高并发操作,比如每秒对PB级数据进行上千次操作;
- 读写访问均是非常简单的操作。
8 墓碑标记
由于所有的存储文件都是不可变的,从这些文件中删除一个特定的值是做不到的,通过重写存储文件将已经被删除的单元格移除也是毫无意义的,墓碑标记就是用于此类情况的,它标记着”已删除”信息,这个标记可以是单独一个单元格、多个单元格或一整行。
参考文献
深入学习HBase架构原理
HBase数据模型解析和基本的表设计分析
HBase 官方文档中文版
HBase简单介绍,发展历史,逻辑视图,物理存储,系统架构
Hbase 设计与开发实战
HBase架构图
深入HBase架构解析(一)
Hbase架构与原理
Hbase 学习笔记:Hbase 概览
HBase–读写数据
HBase -ROOT-和.META.表结构
(一)HBase的特性和架构
HBase系统架构与存储格式