HBase中Memstore简介
2019-01-27
HBase中Memstore对整个系统的性能有着重要的作用,这里将简单介绍一下该模块。
1 Memstore 概述
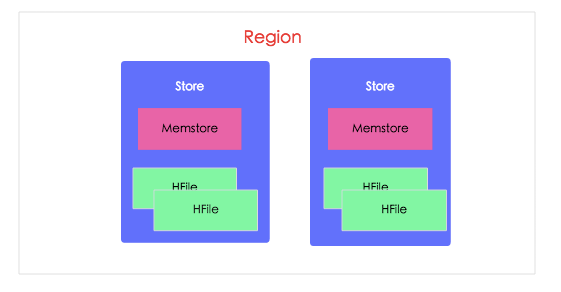
HBase中,Region是集群节点上最小的数据服务单元,用户数据表由一个或多个Region组成。在Region中每个ColumnFamily的数据组成一个Store。每个Store由一个Memstore和多个HFile组成,如下图所示:
HBase是基于LSM-Tree模型的,所有的数据更新插入操作都首先写入Memstore中(同时会顺序写到日志HLog中),达到指定大小之后再将这些修改操作批量写入磁盘,生成一个新的HFile文件,这种设计可以极大地提升HBase的写入性能;另外,HBase为了方便按照RowKey进行检索,要求HFile中数据都按照RowKey进行排序,Memstore数据在flush为HFile之前会进行一次排序,将数据有序化。
2 Memstore Flush触发条件
- Memstore级别限制:当Region中任意一个MemStore的大小达到了上限(
hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新。 - Region级别限制:当Region中所有Memstore的大小总和达到了上限(
hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size,默认2 * 128M = 256M),会触发memstore刷新。 - Region Server级别限制:当一个Region Server中所有Memstore的大小总和达到了上限(
hbase.regionserver.global.memstore.upperLimit * hbase_heapsize,默认 40%的JVM内存使用量),会触发部分Memstore刷新。Flush顺序是按照Memstore由大到小执行,先Flush Memstore最大的Region,再执行次大的,直至总体Memstore内存使用量低于阈值(hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize,默认 38%的JVM内存使用量)。 - 当一个Region Server中HLog数量达到上限(可通过参数
hbase.regionserver.maxlogs配置)时,系统会选取最早的一个 HLog对应的一个或多个Region进行flush - HBase定期刷新Memstore:默认周期为1小时,确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000左右的随机延时。
- 手动执行flush:用户可以通过shell命令 flush ‘tablename’或者flush ‘region name’分别对一个表或者一个Region进行flush。
3 Memstore Flush流程
为了减少flush过程对读写的影响,HBase采用了类似于两阶段提交的方式,将整个flush过程分为三个阶段:
- prepare阶段:遍历当前Region中的所有Memstore,将Memstore中当前数据集kvset做一个快照snapshot,然后再新建一个新的kvset。后期的所有写入操作都会写入新的kvset中,而整个flush阶段读操作会首先分别遍历kvset和snapshot,如果查找不到再会到HFile中查找。prepare阶段需要加一把updateLock对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此持锁时间很短。
- flush阶段:遍历所有Memstore,将prepare阶段生成的snapshot持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘I/O操作,因此相对比较耗时。
- commit阶段:遍历所有的Memstore,将flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,把storefile添加到HStore的storefiles列表中,最后再清空prepare阶段生成的snapshot。