HBase中BlockCache简介
2019-01-27
二八法则:80%的业务请求都集中在20%的热点数据上,因此将这部分数据缓存起就可以极大地提升系统性能。
1 HBase的缓存结构
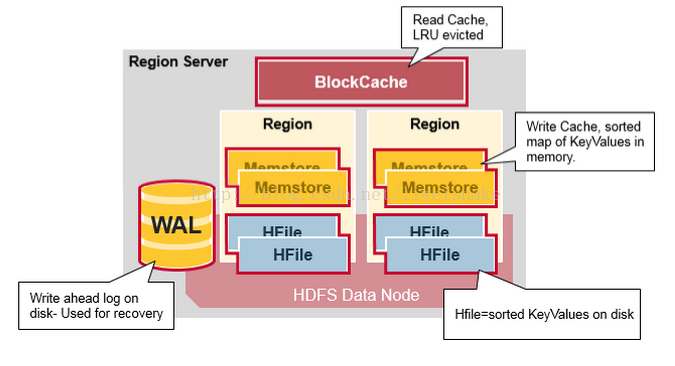
HBase在实现中提供了两种缓存结构:MemStore和BlockCache。
- MemStore称为写缓存,HBase执行写操作首先顺序写入HLog,然后将数据写入MemStore,等满足一定条件后统一将MemStore中数据刷新到磁盘,这种设计可以极大地提升HBase的写性能。不仅如此,MemStore对于读性能也至关重要,假如没有MemStore,读取刚写入的数据就需要从文件中通过I/O查找。
- BlockCache称为读缓存,读请求先到Memstore中查数据,查不到就到BlockCache中查,再查不到就会到磁盘上读,HBase会将查找到的结果缓存到BlockCache,以便后续同一请求或者邻近数据查找请求,可以直接从内存中获取,避免昂贵的I/O操作。
一个Region Server上有一个BlockCache和N个Memstore,它们的大小之和不能大于等于heapsize * 0.8,否则HBase不能正常启动。
BlockCache是Region Server级别的,一个Region Server只有一个Block Cache,在Region Server启动的时候完成Block Cache的初始化工作。
BlockCache 本质上是将热数据放到内存里维护起来,避免 Disk I/O,当然即使 BlockCache 找不到数据还是可以去 MemStore 中找的,只有两边都不存在数据的时候,才会读内存里的 HFile 索引寻址到硬盘,进行一次 I/O 操作。
2 HBase中BlockCache的实现方案
- LRUBlockCache 是最初的实现方案,也是默认的实现方案
- SlabCache
- BucketCache
2.1 区别
这三种方案的不同之处在于对内存的管理模式。
- LRUBlockCache是将所有数据都放入JVM Heap中,交给JVM进行管理。
- SlabCache和BucketCache采用将部分数据存储在堆外,交给HBase自己管理。
这种演变过程是因为LRUBlockCache方案中JVM垃圾回收机制经常会导致程序长时间暂停,而采用堆外内存对数据进行管理可以有效避免这种情况发生。
参考文献
HBase BlockCache系列 – 走进BlockCache
HBase BlockCache系列 - 探求BlockCache实现机制
HBase BlockCache系列 - 性能对比测试报告