线性回归(回归)
1 概述
线性回归模型进行的是回归学习,也就是输出值的预测问题。
假设函数:$h_\theta(x)=\theta^T*x$
代价函数:$J(\theta_0,\theta_1,...,\theta_n)=\dfrac{1}{2m}\sum\limits_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2$
基本思想:我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得代价函数$J(\theta_0,\theta_1,...,\theta_n)$最小。
这里我们可以使用批量梯度下降(batch gradient descent)或正规方程(normal equations)这两种方法来求最小值。
1.1 批量梯度下降
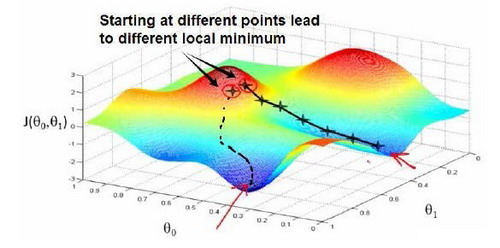
梯度下降背后的思想是:开始时我们随机选择一个参数的组合$(\theta_0,\theta_1,...,\theta_n)$,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
批量梯度下降(batch gradient descent)算法的公式为:
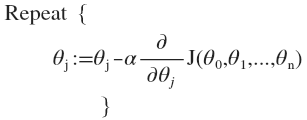
即:
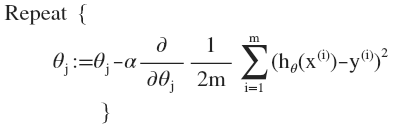
求导数后得到:
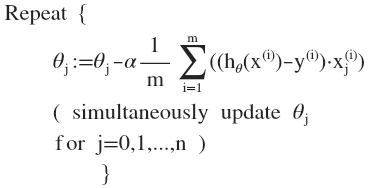
其中$\alpha$是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。从上面公式我们还可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果样本数目$m$很大,训练过程会很慢。
当$n=1$时,批量梯度下降算法中各参数的计算过程如下:

我们开始随机选择一系列的参数值,计算所有的预测结果后,再给所有的参数一个新的值,如此循环直到收敛。
在进行随机梯度下降时,$\alpha$(学习率)的初始选择是否得当对算法收敛是有很大影响的。
- 如果
$\alpha$太小了,即我的学习速率太小,$J(\theta_0,\theta_1,...,\theta_n)$的收敛速度很慢,则达到收敛所需的迭代次数会非常高; - 如果
$\alpha$太大了,那么梯度下降法可能会越过最低点,甚至可能无法收敛。
通常可以考虑尝试些学习率:$\alpha=0.001,0.01,0.1,1$
注意: 如果我们预先选择的$\theta_n$就处于一个局部最低点,根据:
$\theta_n:=\theta_n-\alpha\dfrac{d}{d\theta_n}J(\theta_0,\theta_1,...,\theta_n)$
其中$\dfrac{d}{d\theta_n}J(\theta_0,\theta_1,...,\theta_n)$此时的值为$0$,所以$\theta_n$的值不在变。
总结:
- 优点:全局最优解;易于并行实现;
- 缺点:当样本数目很多时,训练过程会很慢。
1.2 正规方程
公式:$\theta=(X^TX)^{-1}X^Ty$
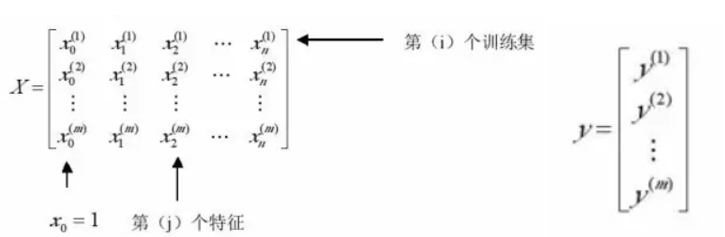
通过正规方程求得的矩阵$\theta$,即为使代价函数最小的参数$(\theta_0,\theta_1,...,\theta_n)$。
注意: 对于那些不可逆的矩阵,正规方程方法是不能用的。
矩阵$(X^TX)^{-1}$不可逆的原因主要有两点:
- 特征冗余:如果两个特征
$(x_1,x_2)$相关,即可表示为$x_2=f(x_1)$,则会造成$(X^TX)^{-1}$不可逆。
解决办法:剔除掉一个特征。 - 特征
$n$远大于训练集个数$m$:如果训练集10个,而特征$x$有100个$(x_1,x_2,x_3,...,x_{100})$。
解决办法:如果可以接受,使用更少的特征建模。
梯度下降与正规方程的比较:
| 梯度下降 | 正规方程 |
|---|---|
需要选择学习率$\alpha$ |
不需要 |
| 需要多次迭代 | 一次运算得出 |
当特征数量$n$大时也能较好适用 |
需要计算$(X^TX)^{-1}$如果特征数量$n$较大则运算代价大,因为矩阵逆的计算时间复杂度为$O(n^3)$,通常来说当$n$小于10000 时还是可以接受的 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数 $\theta$ 的替代方法。具体地说,只要特征变量数量小于一万,通常使用标准方程法,而不使用梯度下降法。
2 总结
- 优点:实现简单,计算简单;
- 缺点:不能拟合非线性数据。
参考文献
斯坦福大学2014机器学习教程中文笔记 第一周
斯坦福大学2014机器学习教程中文笔记 第二周
斯坦福大学《机器学习》课程-中文版笔记(1)
斯坦福大学《机器学习》课程-中文版笔记(2.1)